Self-Distilled Agentic Reinforcement Learning
自蒸馏 Agent 强化学习:解决多轮多步特权指导不稳定问题
作者:Zhengxi Lu, Zhiyuan Yao, Zhuowen Han, Zi-Han Wang, Jinyang Wu 等
机构:浙江大学、美团、清华大学
📄 查看 ArXiv 原文
研究背景与痛点
多轮 LLM Agent 的 RL 后训练面临 reward 稀疏、credit assignment 困难,以及 teacher-student 蒸馏在长轨迹上极易失稳的问题。论文指出,直接把 on-policy self-distillation 套到多轮 Agent 上,容易在 teacher 误导或 student 轨迹偏移时造成灾难性训练崩溃。
核心贡献
- 提出 SDAR:把 RL 作为主目标,把蒸馏降格为可门控的辅助信号。
- 引入 token-level gap gating,对 teacher 真正更优的 token 强蒸馏,对 teacher 明显不靠谱的 token 软抑制。
- 在 ALFWorld、WebShop、Search-QA 上稳定优于 GRPO 和朴素 GRPO+OPSD。
具体案例剖析
在 ALFWorld 中,student 可能不知道先开冰箱,而 teacher 由于拿到 privileged skill 能更高置信度输出 open fridge。若 teacher 真的更好,门控会放大蒸馏;若 teacher 被错误 skill 误导,门控会自动衰减蒸馏,让 RL 信号保持主导。
方法论与技术实现
 图注:SDAR 用 token 级 gate 将 privileged teacher 的指导转成有选择的蒸馏权重,与 GRPO 主损失共同优化。
图注:SDAR 用 token 级 gate 将 privileged teacher 的指导转成有选择的蒸馏权重,与 GRPO 主损失共同优化。
总体目标为:
$$ \mathcal{L}(\theta)=\mathcal{L}_{GRPO}(\theta)+\lambda_{SDAR}\mathcal{L}_{SDAR}(\theta) $$
其中 gap 定义为 teacher 与 student 对当前 sampled token 的 log-prob 差异,并通过 sigmoid 得到 gate:
$$ \Delta_t = \mathrm{sg}(\log \pi^+_\theta(y_t|s_t^+) - \log \pi_\theta(y_t|s_t)) $$
$$ g_t = \sigma(\beta \Delta_t) $$
从而对蒸馏项做细粒度加权,避免 long-horizon teacher error 反向污染 student。
实验设置与结论分析
SDAR 在多个模型规模和多个环境中都更稳健。特别是在较小模型上,朴素混合 RL+OPSD 容易崩,而 SDAR 依然能持续提升;在 WebShop 7B 上还有显著增益。更关键的是,训练时用外部 skills,推理时不挂 skill 也能涨点,说明知识被真正内化。
关键技术亮点分析
这篇工作的价值在于把“RL 主权”和“特权蒸馏辅佐”分开。对工业 Agent RL 而言,这是一种非常务实的范式:teacher 可以引导,但不再拥有一票否决权。
APWA: A Distributed Architecture for Parallelizable Agentic Workflows
APWA:面向可并行 Agent 工作流的分布式架构
作者:Evan Rose, Tushin Mallick, Matthew Laws, Cristina Nita-Rotaru, Alina Oprea
机构:Northeastern University
📄 查看 ArXiv 原文
研究背景与痛点
现有多 Agent 框架通常把 orchestration、状态同步和大规模数据处理耦在一起,面对百万级记录、超长文档、海量网页任务时会产生 context explosion,并且很难把任务真正拆成可大规模并发的子任务。
核心贡献
- 提出 APWA,把 agent 规划层与分布式数据/执行层清晰解耦。
- 引入 Data Tables、Subtask Templates、Lineage 等抽象,让 manager 只处理 metadata 与 contracts。
- 基于 Ray 构建 executor,支持成百上千 worker 并发执行。
具体案例剖析
在 SummaryBench 中,APWA 可以把超大规模分层文档摘要任务拆成海量独立子任务,批量发射 worker 并在上层按 schema 汇总输出,避免 orchestrator 把整份原文都吞进上下文。
方法论与技术实现
系统层包含 manager、worker、executor 三层;分布式层包含 data tables、delegation templates 与 output contracts。manager 不直接操作 raw data,而是操作表与 lineage。
实验设置与结论分析
论文在 SummaryBench、PII-300k、SchemaBench、Web Browsing 等任务中展示了 APWA 的扩展性。在输入规模激增时,baseline 往往因超时或上下文爆炸失效,而 APWA 仍保持很低失败率,并呈现更优的亚线性时延增长。
关键技术亮点分析
它本质上是给 Agent 系统补上“数据面/控制面分离”的基础设施短板。对未来大规模 enterprise agent pipeline 很有现实意义。
Why Neighborhoods Matter: Traversal Context and Provenance in Agentic GraphRAG
为什么邻居很重要:Agentic GraphRAG 中的遍历上下文与出处
作者:Riccardo Terrenzi, Maximilian von Zastrow, Serkan Ayvaz
机构:University of Southern Denmark
📄 查看 ArXiv 原文
研究背景与痛点
GraphRAG 时代的 citation faithfulness 不再只是“最终引用是否支撑答案”。Agent 在图谱里 traversing 时,访问过但没引用的节点、拓扑结构和中间路径,也可能深刻影响答案。只检查最终 citation,会漏掉真正的 provenance。
核心贡献
- 把 Agentic GraphRAG 的 faithfulness 重新定义为 trajectory-level 问题。
- 设计 graph ablation 研究 cited、visited-but-uncited、未访问节点的真实作用。
- 证明 cited evidence 常常是必要但不充分的,邻接结构和中间路径同样重要。
具体案例剖析
例如多跳问答中,agent 最终只引用了答案节点与两个目标实体,但它在搜索过程中可能依赖沿途的导演、演员、社区结构等“未引用节点”来缩小搜索空间。删掉这些节点后,答案可能就变了。
方法论与技术实现
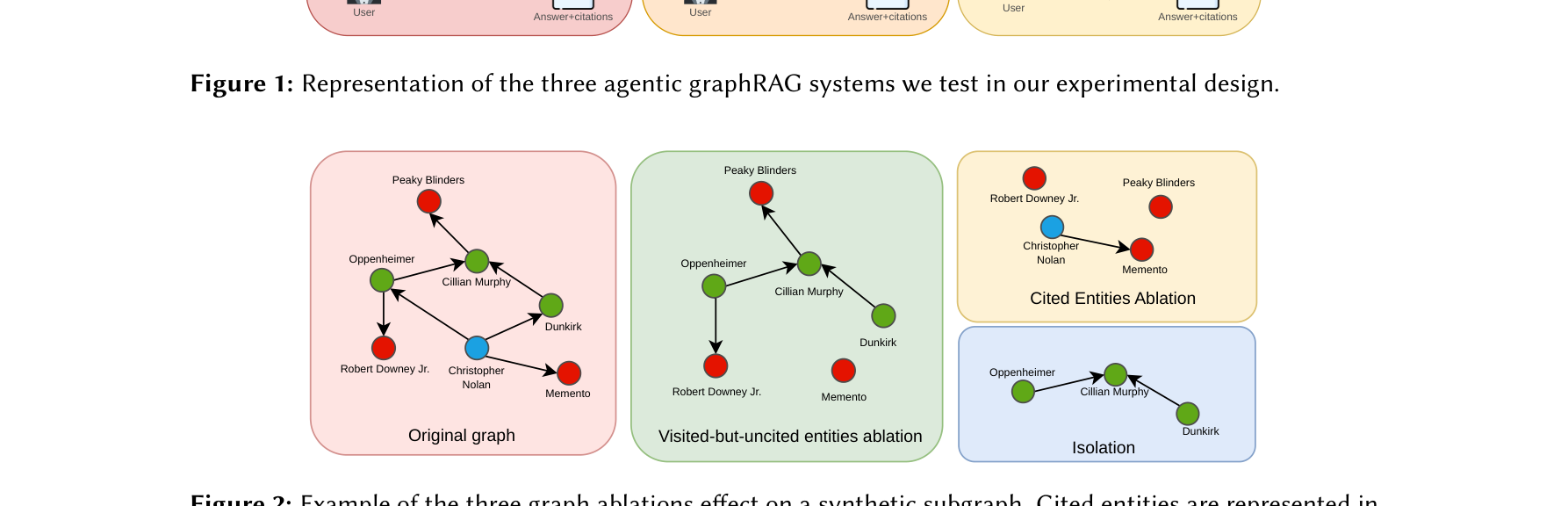 图注:论文用三类 graph ablation 检查 cited 节点、visited-but-uncited 节点以及完整拓扑对 Agent 最终答案的影响。
图注:论文用三类 graph ablation 检查 cited 节点、visited-but-uncited 节点以及完整拓扑对 Agent 最终答案的影响。
作者把节点分成 cited、visited-but-uncited 和 unvisited,并进行 isolation、cited removal、visited entity removal 等消融。结果显示,仅保留 cited 节点不足以完整重建 agent 的推理依据。
实验设置与结论分析
在 2WikiMultiHopQA 构建的图谱环境中,agent 平均访问的实体数远高于最终引用数;移除 cited 节点会显著掉点,而只保留 cited 节点也会显著掉点,说明最终 citation 不是完整解释。
关键技术亮点分析
这篇论文提醒我们:GraphRAG 审计不能只看 answer attribution,还要看 trajectory provenance。对于生产级可解释性评估,这是个很重要的范式更新。
Concurrency without Model Changes: Future-based Asynchronous Function Calling for LLMs
不改模型实现并发:基于 Future 语义的 LLM 异步函数调用框架
作者:Guangyu Feng, Huanzhi Mao, Prabal Dutta, Joseph E. Gonzalez
机构:UC Berkeley
📄 查看 ArXiv 原文
研究背景与痛点
当前 LLM function calling 大多是同步语义:发起一次调用后必须等待返回,严重拉高端到端延迟。即使支持 parallel FC,也多局限于单轮并行,难以跨轮次安全并发,尤其不擅长处理依赖关系与 race condition。
核心贡献
- 提出 AsyncFC,把异步并发能力放在 runtime 层,而不是改模型本身。
- 使用 Future/Promise 风格的占位符,让模型在工具执行期间继续解码。
- 通过 dependency-aware scheduler 和 state tree 管理资源读写依赖。
具体案例剖析
如果 agent 既要抓取财报又要订会议室,传统同步 FC 需要串行等待;AsyncFC 则把两个调用都发出去,立刻向模型返回 future id,等依赖结果准备好后再注入上下文或触发下游调用,显著缩短整体时延。
方法论与技术实现
其理论收益可写成:
$$ R = \frac{T_{LLM}+T_{tool}}{\max(T_{LLM}, T_{cp})} $$
其中 T_cp 是依赖图关键路径耗时。只要工具执行图存在可并行结构,且解码时间能够覆盖部分执行时间,就能接近理想加速。
实验设置与结论分析
在 BFCL、SWE-bench Lite 等任务上,AsyncFC 在不牺牲准确率的前提下实现了可观加速。论文一个很有意思的观察是:现代 LLM 天然就能处理未解析的 symbolic future,这为工程层异步改造提供了很强支撑。
关键技术亮点分析
这项工作非常工程化,但价值很高。它说明提升 Agent latency 不一定要重新训练模型,很多时候把并发控制做在 runtime 就够了,而且更容易落地到真实生产系统。
Orchard: An Open-Source Agentic Modeling Framework
Orchard:一个开源的 Agentic 建模与训练框架
作者:Baolin Peng, Wenlin Yao, Jianfeng Gao 等
机构:Microsoft Research, Columbia University, UIUC
📄 查看 ArXiv 原文
研究背景与痛点
Agent 训练领域长期缺一个统一、可扩展且便宜的基础设施。环境管理、harness、评测流程、RL 数据收集往往高度耦合,切换 benchmark 或任务类型时复用性很差,规模化训练成本也很高。
核心贡献
- 提出 Orchard Env:Kubernetes 原生、极薄的环境服务层,用 runtime injection 与 Pod-IP 直连降低延迟和成本。
- 提出 Credit-Assignment SFT,从失败轨迹中提取仍有价值的上升片段进行监督。
- 提出 BAR(Balanced Adaptive Rollout),缓解长轨迹 RL 中全对/全错导致的低信息 batch 问题。
- 在 SWE、GUI agent、个人助理 agent 等场景展示统一框架的泛化能力。
具体案例剖析
在 GUI agent 任务中,模型以 ReAct 式轨迹与浏览器环境交互:先在 <think> 中锚定当前页面与计划,再输出结构化 <tool_call>。Orchard Env 在沙盒里执行动作并回注 observation,从而形成清晰的训练闭环。
方法论与技术实现
在 SWE 方向,论文使用回顾式价值估计从失败轨迹中提取有贡献片段;在 RL 阶段用 BAR 动态收集具有足够方差的 rollout batch,提高数据效率。
信用分配的思想可写作:
$$ V(s_t)=\mathbb{P}(\mathrm{resolve}\mid h_t, \mathrm{outcome}) $$
再用相邻状态的价值差抽取 rise segments 作为高质量监督片段。
实验设置与结论分析
Orchard 在系统层面显著降低环境延迟与训练成本;在能力层面,SWE、GUI 与个人助理任务都取得很强表现,说明“统一环境层 + 专门训练策略”是可行的 agent 建模路线。
关键技术亮点分析
论文最有启发性的地方是把 infrastructure、trajectory mining、RL sampling 三件事系统化地放在一起看。它不是只做一个 benchmark 提升,而是在搭一个真正可复用的 agent training stack。