Listwise Policy Optimization: Group-based RLVR as Target-Projection on the LLM Response Simplex
列表式策略优化:将基于组的RLVR统一为LLM响应单纯形上的目标投影
作者: Yun Qu, Qi Wang, Yixiu Mao, Heming Zou, Yuhang Jiang 等
机构: 清华大学自动化系、腾讯大模型团队 (Tencent Hunyuan)
📄 查看 ArXiv 原文
🔍 研究背景与痛点
自 DeepSeek-R1 和 OpenAI o1 展现出惊艳的推理能力以来,基于可验证奖励的强化学习(RLVR,Reinforcement Learning with Verifiable Rewards) 已成为激发大语言模型(LLMs)复杂逻辑与数学推理能力的标准后训练范式。在这一浪潮中,无需 Critic 网络的 Group-based Policy Gradient(基于组的策略梯度,如 GRPO) 占据了绝对主导地位。这类方法针对同一个 Prompt 采样 $K$ 个响应(Responses),并利用组内的相对奖励统计量来构建优势函数(Advantage)并更新策略。
尽管社区随后提出了各种 Advantage 归一化的改进版本(例如 Dr.GRPO, MaxRL, REINFORCE++),但痛点在于: 单纯从“优势函数归一化”的经验视角来理解这些算法,掩盖了其背后深层的数学优化机制。这种缺乏根本性理论理解的现状,导致了模型在 RL 训练中经常遭遇过度拟合早停、梯度剧烈波动、策略坍塌(Mode Collapse,表现为生成长度缩短和多样性丧失) 等顽疾。
💡 核心贡献
本文在 RLVR 理论与算法层面做出了极具洞察力的统一与创新:
理论视角的统一(隐式目标投影): 揭示了一个被广泛忽视的几何结构——现有的组级策略梯度方法(如 GRPO 等),本质上都是在 $K$ 个响应构成的“响应单纯形(Response Simplex)”上,隐式地构建了一个以奖励加权的 Gibbs 目标分布,并尝试通过一阶近似 的逆 KL 散度(Reverse KL)进行更新。由于是一阶近似,当策略在训练中偏离采样分布时,近似误差会急剧放大,导致优化失稳。提出 LPO(Listwise Policy Optimization): 作者将上述“隐式的近似”转化为“显式的精确投影”,提出了 LPO 框架。它优雅地将“要追求什么样的目标分布(Target)”与“采用何种路径去靠近目标(Projection)”进行了解耦。优越的数学性质与新发掘的设计空间: 通过在连续的响应单纯形上进行精确的列表式(Listwise)散度最小化,LPO 获得了有界(Bounded)、零和(Zero-sum)和自修正(Self-correcting) 的梯度更新。这不仅天然控制了方差,还允许研究者引入诸如 Forward KL 等全新的投影散度,从而在结构上对抗模式坍塌,保护推理轨迹的多样性。
🛠️ 具体案例剖析
为了直观理解 LPO 的行为方式,我们可以观察模型在逻辑推理与代码生成任务中的表现:
场景一:Countdown (算术倒计时游戏) 探索维持 [2, 54, 17],要求通过加减乘除得到目标值 35。传统的 GRPO 在多次更新后,由于一阶近似带来的偏倚,极易导致策略快速向某个碰巧得分的特定计算路径坍塌(例如过早终止思维链 <think>)。而采用 LPO-fwd (Forward KL) 时,由于 Forward KL 具有 Mode-Coverage(覆盖模式)的几何特性,模型在训练后期依然保持了较高的响应熵(Response Entropy)。这意味着模型在 <think> 过程中会保持生成多条可行逻辑分支的偏好,显著提升了 Pass@k 的成功率。
场景二:代码生成 (PRIME-Code) 中的内部竞争调度 等额转移 给同组中未被充分重视的优质代码。这种类似于“零和博弈”的内部微调,极大稳定了梯度。
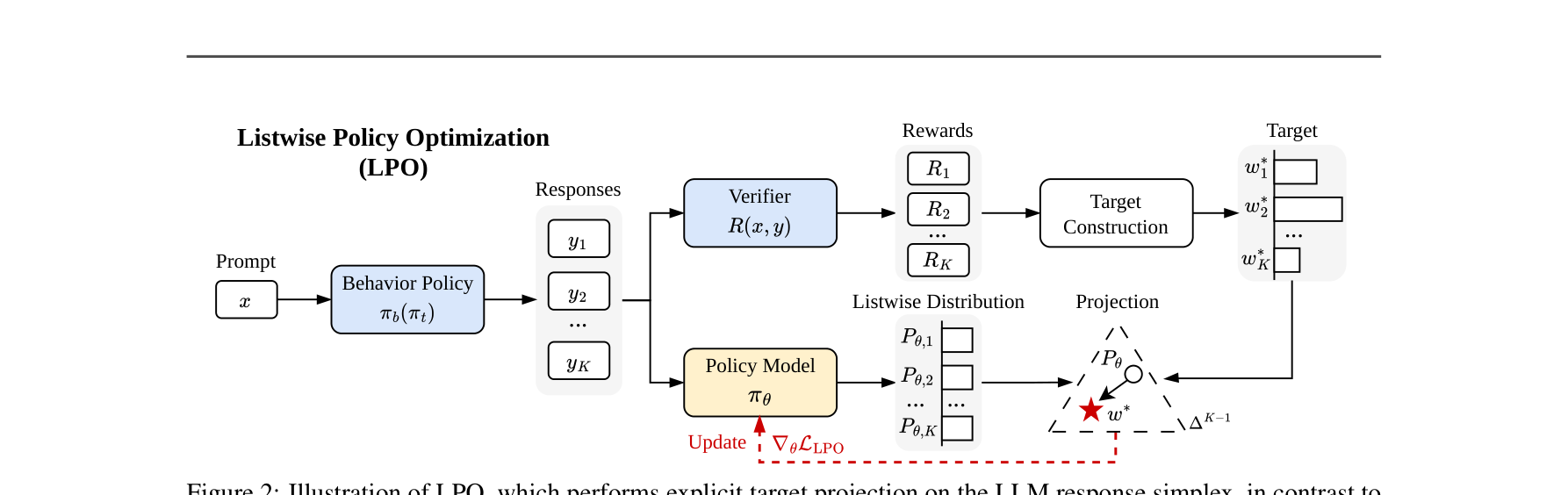
图注:LPO(Listwise Policy Optimization)核心架构:将K个采样响应构建为单纯形上的列表分布,计算Reward并构建目标分布,最后执行解耦的精确散度投影。 ⚙️ 方法论与技术实现
LPO 将传统 RLVR 中纠缠不清的梯度推导,拆解为清晰的两步过程:Target(寻找目标)和 Projection(投影) 。
1. Listwise 分布的定义:
2. 步骤一:显式目标构建 (Target Induced on the Simplex):
3. 步骤二:解耦的策略投影 (Projection for Policy Optimization):
Forward KL ($D_{\text{KL}}(w^* \| P_\theta)$): 梯度权重极其简洁,为 $c_k^{\text{fwd}} = P_{\theta,k} - w^*_k$。Reverse KL ($D_{\text{KL}}(P_\theta \| w^*)$): 梯度权重为 $c_k^{\text{rev}} = P_{\theta,k}(d_k - \bar{d})$,其中 $d_k$ 是当前 logit 与目标 logit 的差异,$\bar{d}$ 是期望差异。
4. LPO 的黄金数学性质: (a) 有界性: $|c_k| \le 1$ 或 $|c_k| \le 2$,这使得模型在极端 Reward 面临“梯度爆炸”免疫;(b) 零和性: $\sum_k c_k = 0$,这是绝佳的内置控制变量(Control Variate),自适应实现基线对齐(Baseline-subtraction),无需引入额外的 Value 模型;(c) 模式覆盖(仅限 Forward KL): 具备保底下界,防止概率被压缩到0,从而保持探索的多样性。
📊 实验设置与结论分析
实验设置: 作者使用 verl 框架,在四个极具挑战的推理任务上进行了评估:逻辑推理 (Countdown)、数学 (MATH)、编程代码 (PRIME)、多模态几何 (Geometry3k)。基座模型涵盖 Qwen 系列 (1.5B 到 14B)、DeepSeek-R1-Distill、Llama-3.1-8B 和 Mistral-7B。对比基线包括设定了不同隐式温度的 GRPO ($\tau=\sigma_G$)、Dr.GRPO ($\tau=1$) 和 MaxRL ($\tau=\mu_G$)。
核心结论:
绝对性能碾压基线: 在匹配完全相同温度 $\tau$ 的设置下,无论是 LPO-fwd 还是 LPO-rev,在预期的 Pass@1 和 Pass@k 上几乎全面超越了与之对应的 PG 隐式基线(15组实验赢下13~15组)。这证明“精确的投影”带来的增益是正交且普适的。Forward KL 展现惊人的探索保留能力: 数据显示,LPO-fwd 往往在 Pass@k 上拔得头筹。监控训练动态发现,LPO 变体的 Response Entropy 远高于 GRPO,并且生成的思考序列(Response Length)显著更长。这是因为 Forward-KL 几何性质拒绝将非零目标压缩到极低概率,有效对抗了 RL 带来的信息熵锐减。梯度极度平滑稳定: 实验中的 Gradient Norm 追踪曲线表明,传统 GRPO 的梯度范数常常出现剧烈的“锯齿状”尖峰,而 LPO 得益于其有界且零和的系数属性,其梯度曲线平滑得多,展现出极强的训练稳定性,极大降低了 RL 调参的崩溃风险。高度可扩展性: 在 53k 规模的 Polaris 数据集上训练 Qwen-14B,LPO-fwd 仅用 70 步就达到了 GRPO 200 步的峰值性能,展现了卓越的样本效率。
🌟 关键技术亮点分析
对于资深 LLM 从业者而言,LPO 最大的启示在于重新审视了现有 Alignment/RLHF 范式中的“近似妥协” 。传统的 PPO 等方法由于要在连续动作空间中运行,不得不对 Policy 采用 Pointwise 的一阶梯度近似。但对于生成式的自回归大模型而言,一次采样生成的 $K$ 条数据,天然构成了一个封闭的有限离散状态空间(单纯形) 。
LPO 巧妙地抓住了这个特性,把传统在连续域无法算尽的配分函数(Partition Function),降维在小批量生成的 Response 集合内精确计算。这把 RLVR 从“蒙着眼睛摸着石头过河(一阶策略梯度)”变成了“睁开眼睛看着地图直接瞬移(单纯形显式散度投影)”。
更为重要的是,LPO 实现了目标空间和优化路径的解耦 。这意味着,未来我们可以设计动态调度的策略(例如早期使用 LPO-fwd 广泛铺开多条推理分支,后期切换至 LPO-rev 锁定最高效的证明路径),或者针对特定任务设计全新的散度,这为被 GRPO 统治的 LLM 强化推理后训练领域打开了极具想象力的全新设计空间。
AGPO: Asymmetric Group Policy Optimization for Verifiable Reasoning and Search Ads Relevance at JD
AGPO:用于可验证推理与京东搜索广告相关性的非对称组策略优化
作者机构: Yang Xu, Kun Yao, Yiming Deng, Zheng Fang, Kai Ming Ting, Ming Pang (南京大学, 北京大学, 京东集团)
论文链接: 📄 查看 ArXiv 原文
🔍 研究背景与痛点 (Background & Pain Points)
基于可验证奖励的强化学习(RLVR,Reinforcement Learning with Verifiable Rewards)已成为提升大语言模型(LLMs)逻辑推理能力的标准范式(如 OpenAI-o1, DeepSeek-R1)。然而,业界在落地 RLVR 时逐渐发现一个致命痛点:推理能力边界收缩(Reasoning Boundary Shrinkage) 。
痛点一:过度优化与分布坍塌。 当前主流 RL 算法(如 PPO, GRPO, REINFORCE)本质上是“识别并放大(Identify-and-Amplify)”机制。它们通过给予正确路径正奖励,导致模型输出分布急剧向高频、简单的正确路径(Trivial Paths)坍塌。痛点二:Pass@k 逆向退化。 虽然标准 RLVR 能显著提升模型的 Pass@1(贪心解码准确率,即采样效率),但在大样本量下(Pass@256),其覆盖的正确解空间反而不如未经 RL 训练的 Base 模型 。模型丧失了探索复杂、罕见正确路径(Rare Correct Paths)的能力。痛点三:纯负样本强化(NSR)的局限性。 近期研究发现仅依赖负反馈(NSR)虽能保护推理边界,但会导致收敛缓慢且训练不稳定;而在冷启动阶段,单纯依赖 NSR 无法建立有效的正向推理模式。
💡 核心贡献 (Core Contributions)
为了在提升 Pass@1 采样效率的同时,最大程度保护甚至拓宽模型的推理能力边界(Pass@k),本文提出了一种全新且优雅的强化学习对齐算法——非对称组策略优化 (AGPO, Asymmetric Group Policy Optimization) 。
提出非对称优势估计算法(AGPO): 采用“负反馈主导(NSR-dominated)”策略来抑制错误路径,同时针对正反馈采用动态组相对优势机制,给予罕见正确路径高奖励,对平凡简单正确路径实现零干预,从而保持模型探索熵。全面验证了对数学推理边界的保护: 在 MATH、Olympiad、AIME-2024 等五大数学基准上,不仅取得了 SOTA 的 Pass@1 成绩,还在大采样预算(Pass@256)下稳稳超越 GRPO 等基线,彻底逆转了能力边界收缩现象。成功落地超大规模工业级检索场景: 将该方法应用于京东搜索广告的 Query-SKU 相关性判断,通过对 Teacher 模型(Rele-Ads-8B)的 RLVR 训练,极大优化了蒸馏数据质量,在线上 A/B 测试中实现了核心商业指标(CTRPI, CPM, GMV)的全面正向增长。
🔎 具体案例剖析 (Case Study)
为了直观展现 AGPO 如何引导模型进行高质量、精细化的逻辑推理,我们提取了其在京东搜索广告相关性(Search Ads Relevance) 任务中的具体表现。该任务要求大模型基于复杂的电子商务规则输出 CoT(思维链)并给出相关性判定。
[输入] 用户查询 (Query) 与 候选商品 (SKU) 对: [AGPO 优化的 Rele-Ads-8B 模型的 CoT 推理输出]: 输出分析: 我们首先分析产品词匹配情况,query要求产品为"妈妈装",sku对应产品为"中老年羽绒服",属于妈妈装的子类,因此产品词匹配类型为 -> <产品词完全相关> 。<无属性词> 。<完全相关> 。
解读: 该案例展示了 AGPO 训练后的模型在应对“包含干扰实体(广州十三行)与抽象品类泛称(妈妈装)”时的强大鲁棒性。传统 RL 训练往往会让模型死记硬背高频 Query-SKU 匹配特征,而 AGPO 使得模型能够稳定探索并遵从规则链条(先产品词定性 -> 后属性词过滤去噪),从而在工业长尾分布上保持极高的准确度(极低的 PIR)。
⚙️ 方法论与技术实现 (Methodology)
传统的 GRPO 优势函数是对同一 Prompt 下生成的 $G$ 个样本的奖励($0$或$1$)直接进行 Z-Score 标准化。这种做法是对称的,且会过度奖励那些在当前策略下已经具备高置信度(即容易被采样到)的“平凡正确路径”。
AGPO 的核心是将优势函数的计算进行非对称解耦(Asymmetric Decoupling) ,其优势函数定义如下:
$\hat{A}_i^{\text{AGPO}} = \underbrace{\frac{1}{\sqrt{\sigma^2 + \delta^2}} \cdot (r_i - \mu)}_{\text{受限组相对项 (Constrained group relative term)}} + \underbrace{\mathbb{I}(r_i < 0) \cdot \mathcal{R}}_{\text{门控负项 (Gated negative term)}}$
门控负项 (Gated negative term): 通过常数 $\mathcal{R}$(实验中设为 $-1$),为所有错误输出提供稳定、强力的负向惩罚。即使组内所有输出均错误,也能确保模型持续修剪错误搜索空间。这构成了 AGPO “NSR (负反馈) 主导” 的特性。受限组相对项 (Constrained group relative term): 对于正确的采样路径($r_i=1$),其正向优势不再是固定的,而是受到 $\mu$(组内正确率)和 $\sigma$(标准差)的调节。当某个 Prompt 极易答对时(即所有样本都对,$\mu \to 1, \sigma \to 0$),正向优势会被压缩至 $0$(由于 $\delta$ 的存在不会除零异常)。方差正则化因子 $\delta$: $\delta$ 作为一个平滑参数,限制了奖励振幅,有效防止了正样本更新引发的概率分布过度锐化(Over-sharpening)。
优化机理总结: AGPO 实现了一种“难例重赏、易例零干预”的聪明机制。对于模型已经掌握的简单问题,停止注入正梯度;对于偶尔碰对的 rare correct paths($\mu$ 极低),给予最高奖励;而无论何时,坚决打压错误路径。这极大地保护了策略输出的熵值,使得模型在持续优化的同时保留了广阔的解空间探索能力。
📊 实验设置与结论分析 (Experiments & Results)
论文在开源模型(Qwen2.5-Math-7B, Qwen3-4B, Llama-3.1-8B-Instruct)上进行了广泛评测,实验结论极具说服力:
数学基准全面霸榜 (Math Benchmarks): 在 MATH、Olympiad、AIME-2024 等数据集上,AGPO 的 Pass@1 全面超越 PPO、GRPO 和 REINFORCE。更关键的是,在 $k=256$ 时,PPO/GRPO 相较于 Base 模型出现了明显的性能倒退(如 MATH 从 96.7% 掉到 94.7%),而 AGPO 维持在了 96.6% 的高水位,几乎完全克服了推理边界收缩 问题。工业场景的线下提效 (Offline JD Ads Evaluation): 在京东搜索广告 Rele-Ads-8B 教师模型的训练中,AGPO 显著降低了 PIR(无关商品曝光率,即 Bad Case 占比),从 Base 模型的 7.2% 下降到 5.4%,同时在 Pass@4 上表现出最强的鲁棒性(85.0%)。工业线上真实收益 (Online A/B Test): 通过 AGPO 优化后的教师模型重打标签,蒸馏至线上的 BERT 轻量化排序模型。为期两天的严格 A/B 测试显示,CTRPI(单次曝光点击率)提升 0.22%,CPM(千次展现收益)大幅提升 0.50%,GMV 增长 0.21% ,证明了该方法直接转化为商业真金白银的能力。
🌟 关键技术亮点与从业者洞察 (Key Takeaways)
动态熵保护机制是 RLVR 的长期命门: 实验中的“训练动态分析 (Fig 3c)”揭示了一个惊人的现象——PPO 和 GRPO 在训练几百步后,模型的输出熵会断崖式暴跌(分布坍塌),这解释了为什么它们会丢掉 Pass@256 的性能。而以 NSR 主导的 AGPO,其训练过程中的熵值甚至能维持在 Base 模型基线之上,这是它能兼顾“开采”与“探索”的核心依据。去除 KL 散度约束的可能性: 传统 PPO/GRPO 高度依赖 KL 惩罚项($\beta \cdot \mathbb{D}_{KL}$)以防止模型跑飞。但论文通过消融实验证实:在 NSR 主导的非对称更新(如 AGPO)下,策略的安全性天然得到保障,甚至将 $\beta$ 设为 0 能取得最优表现 。这极大释放了算法对参考模型的内存依赖。警惕“冷启动约束 (Cold-Start Problem)”: 论文指出,所有 On-policy RLVR 算法(包含 AGPO)的性能天花板,均取决于 Base 模型的初始探测能力。如果在 AIME-2025 这种地狱难度基准上,Base 模型初始 Pass@1 为 0,模型将在长达数百步内收集不到任何正反馈,导致训练停滞。因此,SFT(冷启动预热)依然是现阶段高阶 RLVR 成功的前置护城河。
Nonsense Helps: Prompt Space Perturbation Broadens Reasoning Exploration
无意义内容有奇效:提示空间扰动拓宽大模型推理探索
作者:Langlin Huang, Chengsong Huang, Jinyuan Li, 等
机构:Washington University in St. Louis
📄 查看 ArXiv 原文
📍 1. 研究背景与核心痛点
近年来,结合规则验证的强化学习(RLVR,如 Group Relative Policy Optimization, GRPO)在提升 LLM 推理能力(特别是数学和代码领域)方面取得了巨大成功。DeepSeekMath 和 Qwen-Math 系列均深度依赖此范式。然而,在面对高难度推理任务(如 AIME)时,GRPO 面临一个极其致命的瓶颈:
Zero-advantage Problem(零优势问题) :当模型面对一道超出其当前 Policy 舒适区的难题时,采样生成的 $G$ 个 Response(通常 $G=8$)很可能全军覆没(Reward 全为 0 或负的格式分)。算力浪费与训练信号丢失 :在 GRPO 框架下,Advantage 是基于 group 内的 Reward 标准化计算的。如果大家 Reward 都一样差,Relative Advantage 就会集体塌陷为 0。这意味着不仅这批极其昂贵的 Rollout 算力打了水漂,而且针对这道难题的梯度更新完全失效,模型永远学不会它不会的东西。
传统解法的局限性: 常规手段是增加采样预算(Adaptive Rollout Budget)或拉高温度(High Temperature)。但这只是在 Logit Space(逻辑空间) 进行探索。对于真正 hard 的问题,模型已经陷入了 local reasoning basin(局部推理盆地),单靠 Logit 级别的抖动极难让其跳出思维定势,重采样成功率依然极低,且高温容易导致推理链(CoT)崩溃。
🚀 2. 核心贡献
本文提出了一种打破常规的思路:既然 Logit 空间的探索不够,不如尝试 Prompt Space Perturbation(提示空间扰动) 。作者提出了 LOPE (Lorem Perturbation for Exploration) 训练框架:
“废话”变宝藏 :在输入 Prompt 之前,随机拼接一段无意义的 Lorem Ipsum (一种伪拉丁语占位符)。这种与任务无关的文本扰动能充分改变模型的初始隐状态和输出分布,解锁正交推理路径 (Orthogonal Reasoning Pathways) ,大幅提高硬核问题的 Resample 成功率。完善的 Off-policy RLVR 方案 :提出了一套优雅的重采样、响应重组(Response Regrouping)、伪 Rollout 构造机制,并配合 Training Signal Shaping(训练信号塑形) 技术,彻底解决了非同策略学习带来的梯度发散和稀有成功样本优势被低估的问题。本质剖析(What makes a good noise?) :不仅停留在打榜,文章深入探究了为何 Lorem Ipsum 有效,定义了优质提示扰动的两大要素:低困惑度(Low Perplexity) 与 弱语境干扰(Pseudo-Latin vocabulary) 。
🔍 3. 具体案例剖析 (Case Study)
为了直观感受 LOPE 的工作原理,我们来看一个它注入 Prompt 时的实际形态(提取自附录):
System Prompt / Input: in laboris velit ex est ex est exercitation sint ex enim ut incididunt tempor cupidatat nisi occaecat deserunt laboris quis voluptate qui consequat proident minim pariatur velit est aliquip do labore ut dolor et ullamco proident in non culpa est amet ipsum officia velit... (省略百字左右随机采样的 Lorem Ipsum) User:
现象解析: 这段前置的亮橙色文本对人类而言纯属“废话乱码”,但对 Transformer 架构的 LLM 而言,它在自注意力机制中相当于注入了一种“结构化的系统噪声”。当模型在标准的 Prompt 下陷入死胡同时,这段噪声能微妙地改变 KV Cache 的注意力权重分配分布,使得模型在生成 <think> 阶段时,走向一条与之前 8 次全错尝试截然不同的推导路线,最终偶然命中正确答案,从而拯救了 Zero-advantage 僵局。
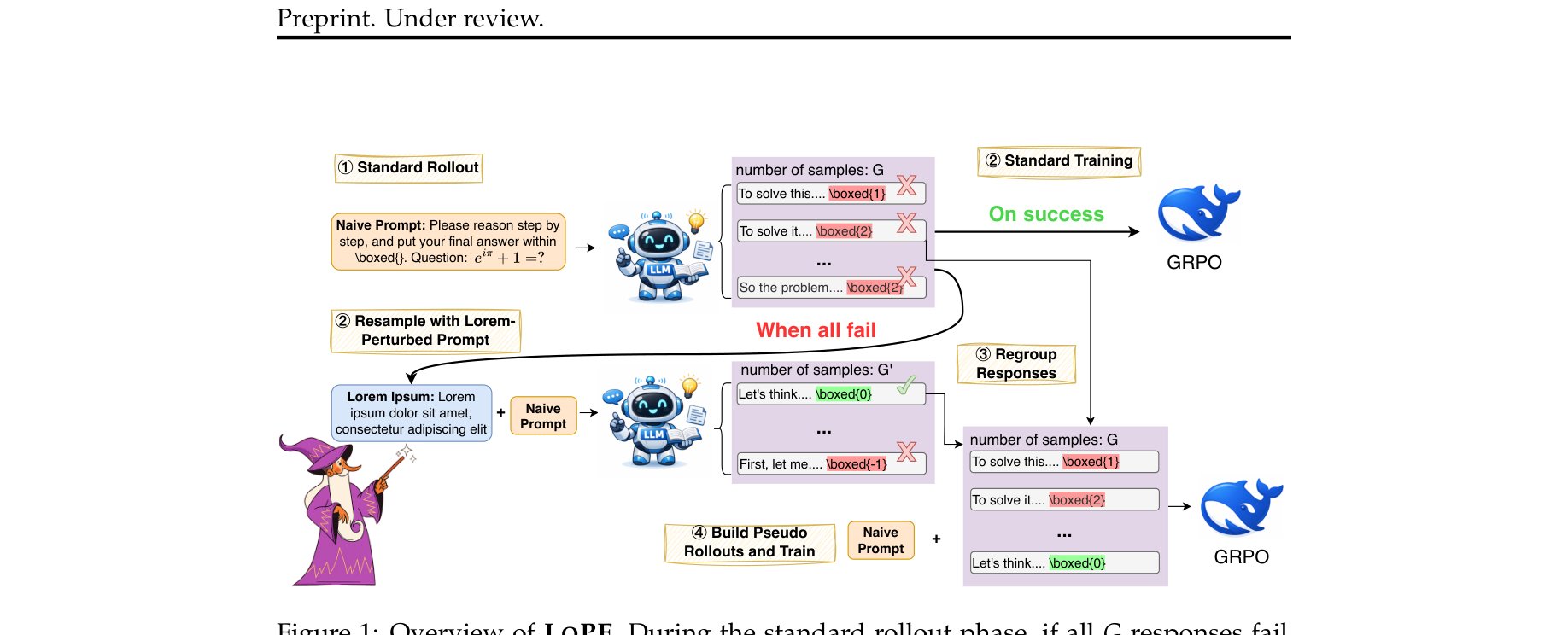
图注:LOPE 框架概览。当标准 Rollout 阶段的 G 个回答全部失败时,LOPE 会在 Prompt 前拼接随机的 Lorem Ipsum 序列并重新采样 G' 个回答。成功的回答将被提取出来,与最初失败的回答重组(Regroup),形成混合 Batch,替换回 Naive Prompt 构建 Pseudo Rollout 进行强化学习梯度更新。 LOPE 的技术流水线由以下几个核心步骤构成,尤其是在 RL 梯度修正上做得非常细腻:
扰动重采样 (Rollout with Perturbation) :当标准 Policy $\pi_{\theta_{old}}(o \mid p, q)$ 生成的 $G$ 个样本全错时,引入随机采样的 Lorem Ipsum $\delta$,拼接得到 $\delta \oplus p$。基于新 Prompt 采样 $G'$ 个($G'=24$)新响应。构造伪 Rollout 组合 (Construct Pseudo Rollout) :从重采样中挑出 $c$ 个回答正确的样本。为了防止因输入上下文($\delta \oplus p$ 与 $p$)不一致导致的 Advantage 估算偏差,LOPE 强行将这些正确响应的 Prompt 替换回原始的 Naive prompt $p$ ,并与原始的错误样本混合,凑成新的 batch(大小仍为 $G$),使得一个 batch 内部既有对又有错,激活有效的 relative advantage。重要性采样修正 (Importance Sampling) :因为用 $\delta \oplus p$ 采样的输出放在了 $p$ 下训练,构成了典型的 Off-policy 场景。因此,需要计算重采样响应的重要性采样率:
🔥 训练信号塑形 (Training Signal Shaping) :这是保证 LOPE 能收敛且起效的灵魂技术:
Policy Shaping (策略塑形) :Off-policy 下,模型对刚探索出来的罕见正确推理 token 赋予的概率 $\pi_\theta$ 极低,导致梯度消失。引入塑形函数 $f(\rho_{i,t}) = \frac{\rho_{i,t}}{\rho_{i,t} + \gamma}$($\gamma=0.1$),强行放大这些低概率(但在探索中被证明有效)token 的梯度权重。Advantage Shaping (优势塑形) :如果在 $G$ 个提取出来的样本内算 advantage,会严重低估该题目的难度(因为那是从上百个废样本里淘出来的)。LOPE 改为在完整的 $G + G'$ 个样本池中计算标准化统计量:
最终优化目标: 包含了标准 GRPO 的 On-policy 失败样本更新,以及经过 $f(\rho_{i,t})$ 修正和 $\hat{A}_i$ 放大的 Off-policy 重采样成功样本更新。
📊 5. 实验设置与结论分析
实验在当前最主流的 Qwen3-1.7B-Base, 4B-Base 和 Qwen2.5-Math-7B 上开展,使用 OpenR1-Math-46k 数据集,测试基准包括 MATH-500, GSM8K, AMC, 和极具挑战的 AIME。
极致提升: 在 7B 模型上,LOPE 配合 Signal Shaping 的平均分数达到了 53.88,远超标准 GRPO 的 47.68(大涨 6.20 个点)。尤其在 AIME24 上从 17.66 提升至 19.58,AIME25 上从 9.90 暴涨至 16.51。Resample 胜率碾压: 训练过程中的监控曲线表明,高温采样(Temp=1.2)或 Naive 重采样在遇到硬骨头题目时,依然是平庸的成功率。而 LOPE 始终能把 Question-Level 的 Resample Success Rate 维持在高位,确保了更多、更难的题目有优质训练信号注入网络。Shaping 的必要性: 消融实验证明,如果不加 Training Signal Shaping,7B 模型的表现甚至略逊于基线(47.32 vs 47.52)。这说明“探索出好样本”只是第一步,“如何吃透 Off-policy 的好样本(梯度的使用效率)”同样决定成败。
💡 6. 关键技术亮点分析:What Makes a Good Prompt Space Perturbation?
最令从业者好奇的是:随便塞段乱码也能行吗?为什么偏偏是 Lorem Ipsum?作者在 Section 7 进行了地毯式的消融验证,测试了 Fake English(假英文)、Random ASCII(随机符号)、Random Token(随机词表)、Latin Unigram(拉丁单词拼凑)等各种噪声。
实验揭示了一个顶级实战 Insight——优质噪声必须具备两大特征:
避免核心语境干扰(Use Pseudo-Latin / Non-English): 用假英文(Fake English)或高频英文单字组成的噪声表现不佳,因为英语噪声会和下游的英文数学题目在 Attention 计算中产生“语义纠缠”,带偏模型的推理逻辑。而拉丁语作为外星语(对这道题而言),能做到“只扰动分布,不篡改语义”。维持低困惑度(Low Perplexity): 模型对输入特征是有流形(Manifold)期望的。Random Token(纯随机词表抽样)的 Perplexity 达到了极其夸张的 $4.6 \times 10^5$。t-SNE 可视化证明,这种极度 Out-of-Distribution 的噪声彻底破坏了输入问题本身的语义表征,导致性能崩盘。而 Lorem Ipsum 的 Perplexity 仅为 25 左右(接近自然语言的 4.8),它是一段“符合自然语言统计学规律的废话”。
总结而言: 在进行 RL 探索时,我们要的不是破坏性的“乱码”,而是一种“温和的、不相干的结构化背景音”。LOPE 用几乎零成本的方式,证明了 Prompt 空间扰动是在 RLVR 时代打破模型探索天花板的绝佳 baseline。
LANTERN: LLM-Augmented Neurosymbolic Transfer with Experience-Gated Reasoning Networks
LANTERN:基于经验门控推理网络的LLM增强神经符号迁移学习
作者: Mahyar Alinejad, Yue Wang, Amrit Singh Bedi, George Atia
机构: University of Central Florida (UCF)
📄 查看 ArXiv 原文
背景与痛点 (Background & Pain Points)
在强化学习(RL)中,为了解决长周期、非马尔可夫(Non-Markovian)的复杂任务,神经符号强化学习(Neurosymbolic RL) 被广泛采用。它通过引入确定性有限自动机(DFA)或奖励机(Reward Machines)来编码时间逻辑结构,并构建乘积马尔可夫决策过程(Product MDP)以提升样本效率。
然而,在将迁移学习(Transfer Learning)引入神经符号RL时,现有方法面临三个核心痛点:
高度依赖人工专家设定(Manual Specification): 传统方法通常需要领域专家手动设计DFA或定义复杂的时间逻辑公式,这在开放环境或探索性RL场景中极难扩展。单源迁移瓶颈(Single-source Transfer Limitations): 现有的自动机蒸馏(Automaton Distillation)或策略蒸馏方法多假设存在一个高度对齐的“单一源任务(Single source task)”。当目标任务与源任务的目标或结构发生变化时,这种硬核复用会大打折扣,甚至导致负迁移。知识融合机制固化(Fixed Integration Mechanisms): 在整合“教师(源策略)”与“学生(目标策略)”的指导信号时,常采用静态超参数或仅依赖经验指标(如TD误差),缺乏对跨任务语义相关性动态变化的适应能力。
核心贡献 (Core Contributions)
本文提出了一种统一的多源神经符号迁移学习框架——LANTERN(LLM-Augmented Neurosymbolic Transfer with Experience-gated Reasoning Networks) ,其核心贡献包括:
问题重构: 将多源神经符号迁移形式化为一种“异构目标语义聚合”问题,而非单一源策略或自动机的直接复用,使其能从多个部分相关的源任务中提取互补知识。LLM驱动的零样本自动机生成: 直接利用大语言模型(LLM)将自然语言任务描述解析为DFA及其状态的语义描述,彻底摆脱人工设定。多源语义聚合与自适应信任门控(Dual-Volatility Gating): 在自动机状态上构建共享的语义嵌入空间(Semantic Embedding Space),通过计算跨任务相似度来加权多个源任务的策略;同时结合TD误差的经验波动率 与跨任务的语义波动率 ,动态决定学生网络在何时、多大程度上听取教师指导。显著提升样本效率: 在资源管理、导航与控制等多类环境中,相比现有Baseline及单源迁移方法,LANTERN实现了40%–60%的样本效率提升,且对未对齐的源任务展现出了极强的鲁棒性。
具体案例剖析 (Case Study: Dungeon Quest)
为直观理解LANTERN如何工作,我们来看论文中的 Dungeon Quest (地牢探险) 案例:
目标任务输入 (Target Description): "Navigate dungeon to collect key and shield, then open chest for sword, finally defeat dragon"(在迷宫中收集钥匙和盾牌,接着开箱拿剑,最后击败龙)。LLM生成的DFA输出:
状态 (States): $\omega_0$ 到 $\omega_4$转移逻辑 (Transitions): $\omega_0 \xrightarrow{\text{key}} \omega_1 \xrightarrow{\text{shield}} \omega_2 \xrightarrow{\text{sword}} \omega_3 \xrightarrow{\text{dragon}} \omega_4$语义描述 (Descriptions): 例如 desc(\omega_1) = "collect key"(关键步骤:不仅生成结构,还赋予自然语言语义)。
多源异构迁移过程:
此时我们有几个毫不相干的源任务策略:如 Source 1 (救援任务) 目标是找地图、救人;Source 2 (寻宝任务) 目标是找线索、挖宝。这两个任务里都没有“龙”或“剑”。“拼图式”的跨任务知识复用 。
方法论与技术实现 (Methodology)
LANTERN 框架分为五个关键阶段,将宏观的符号推理与微观的神经网络TD更新解耦并重新融合:
Phase 1: LLM增强的自动机生成
给定目标任务语言描述 $\mathcal{T}_{desc}$,通过构建结构化Prompt,引导大语言模型 $\mathcal{L}$ 提取子目标、时序依赖,生成目标DFA $\mathcal{D}^{tgt}$。更重要的是,LLM需要为每个自动机状态 $\omega \in \Omega^{tgt}$ 生成语义描述 $\text{desc}^{tgt}(\omega)$。这为后续异构迁移奠定了文本空间的基础。
Phase 2: 语义嵌入与邻域构建
使用文本嵌入模型(如Sentence-BERT)计算自动机状态描述的嵌入:$\phi(\omega) = \mathcal{E}(\text{desc}(\omega)) \in \mathbb{R}^d$。
Phase 3: 多源知识聚合 (Multi-Source Aggregation)
LANTERN 同时聚合战略层(Strategic, 自动机级别的长期价值) 与战术层(Tactical, 动作级别的策略分布) :
战略聚合: $Q_{AD}^{agg}(\omega^{tgt}) = \sum w(\dots) Q_{k, AD}(\omega_k^{src})$战术聚合: $\pi_{teacher}^{agg}(a|s, \omega^{tgt}) = \sum w(\dots) \pi_k^{teacher}(a|s_k, \omega_k^{src})$
Phase 4: 双重波动经验门控 (Dual-Volatility Experience Gating)
如何决定学生何时该“独立思考”,何时该“抄作业”?LANTERN引入了复合信任门控:
经验波动率(Experience Volatility): 追踪TD误差的指数移动平均 $V_t^{exp}(s,a)$。波动率高代表学习不稳定,此时应依赖教师。语义波动率(Semantic Volatility): 量化目标状态与最优源状态之间的“语义错位”:$V^{sem}(\omega^{tgt}) = 1 - \max \text{sim}(\omega^{tgt}, \omega_k^{src})$。两者通过Sigmoid转换为信任系数 $\tau_{exp}$ 和 $\tau_{sem}$,最终门控值 $\tau = \tau_{exp} \times \tau_{sem}$。即只有在学习不稳定 且 语义高度对齐时,才给予教师强权重。
Phase 5: LANTERN 统一更新规则
学生网络的Q-learning更新公式整合了上述多源指导 $G_{multi}$(包含战略激励与战术KL散度惩罚):
$$ \Delta Q = \alpha \left[ \tau \cdot \delta_t + (1 - \tau) \cdot G_{multi} \right] $$
当 $\tau \to 1$ 时,退化为标准TD更新(学生主导);$\tau \to 0$ 时,完全受教师指导。
实验设置与结论分析 (Experiments & Results)
研究团队在离散状态的Product MDP上评估了两种结构差异巨大的环境:
Dungeon Quest (探险导航): 强调严格的时序前置依赖(如拿了钥匙才能开锁)。Blind Craftsman (工匠资源管理): 涉及库存约束的多周期循环采集与制作。对比 Baseline: No Transfer (无迁移)、Automaton Distillation (AD,单源自动机蒸馏)、CADENT (单源经验门控迁移)、LARM (单源LLM自动机生成+奖励塑形)。
核心结论:
样本效率碾压: LANTERN 在 Dungeon Quest 中最终奖励比无迁移方案高 38%,并在学习初期(前500 Episode)相比最强单源Baseline(CADENT和LARM)有 15%~42% 的提升。在 Blind Craftsman 跨领域语义迁移中依然实现了 32% 的改进。消融实验证明多组件的必要性:
Multi-source vs. Single-Source: 多源聚合比单源提升了 26% 。证明了“拼接部分知识”远优于“死磕一个相似的源任务”。Dual-volatility vs. Experience-only: 引入语义波动率控制后性能提升了 18% 。这一机制有效防止了在“源-目标错位区域”发生的负迁移(Negative Transfer)。Strategic+Tactical vs. Strategic-only: 宏观抽象与微观动作级蒸馏缺一不可,两者协同带来 31% 的效率提升。
💡 资深从业者视角:技术亮点分析 (Key Takeaways for LLM Practitioners)
LLM 视角的升维:不只是零样本Planner,而是“语义粘合剂”。 很多工作用LLM做Reward Shaping或直接写代码(如Eureka)。LANTERN 的聪明之处在于,让LLM生成DFA并强制附加状态的自然语言描述 。借由 Sentence-BERT 等文本嵌入空间,模型硬生生在毫不相干的离散MDP任务之间搭建了一座“语义桥梁”。这为跨域强化学习提供了一个极其优雅的潜空间(Latent Space)。双重门控机制(Dual-Volatility Gating)解决了LLM与RL结合的核心痛点——“幻觉式误导”。 在多源任务中,有些子任务根本没有匹配的源策略(比如源任务里都没有打龙的经验)。通过 $V^{sem}(\omega^{tgt}) = 1 - \max \text{sim}$,框架能够在发现“没有匹配语义”时,自动且平滑地掐断(Gating)先验经验的干扰,让RL降级为标准探索。这种“Graceful Degradation(优雅降级)” 机制在真实业务场景极其重要。未来的演进方向: 当前的LANTERN主要在表格型(Tabular)MDP和离散动作空间中验证,依赖精确的状态Labeling。其架构理念完全可以扩展到基于Deep RL的连续控制域(Deep Function Approximation),只要结合现有的视觉-语言模型(VLM)进行在线的零样本状态打标,该框架极具成为通用机器人(Generalist Robot)技能迁移范式的潜力。
AEM: Adaptive Entropy Modulation for Multi-Turn Agentic Reinforcement Learning
中文标题: AEM:面向多轮智能体强化学习的自适应熵调制
作者: Haotian Zhao, Songlin Zhou, Yuxin Zhang 等 (Baidu, Tsinghua University, Fudan University 等)
核心标签: Agentic RL, Multi-turn Interaction, Credit Assignment, Entropy Modulation, GRPO
📄 查看 ArXiv 原文
1. 研究背景与痛点 (Background & Pain Points)
随着大语言模型 (LLMs) 向能够解决复杂任务、调用工具并与外部环境持续交互的智能体 (Interactive Agents) 演进,强化学习 (RL) 已成为提升这类 Agent 核心能力的主流范式。在后训练 (Post-training) 阶段,以 GRPO 为代表的群组化无价值网络优化方法展现出了巨大的潜力。
然而,在多轮智能体强化学习 (Multi-Turn Agentic RL) 设定下,由于环境反馈具有极度的延迟性和稀疏性 (Sparse Outcome-only Rewards) ,传统 RL 算法面临着严峻的信用分配 (Credit Assignment) 难题:
粗粒度反馈的困境: 智能体往往只能在完成数十个交互轮次后获得最终的二元或标量奖励,同一轨迹中的每一个中间步骤都被赋予了几乎相同的学习信号,导致优化方向模糊,策略提升效率低下。现有方案的局限:
引入过程奖励模型 (PRMs) 提供密集监督,但这极大增加了标注成本和调参复杂度。基于树结构的优化 (Tree-GRPO 等) 虽然能细化信用传播,但在多轮交互中会引发组合爆炸级的计算开销。纯自监督方法 高度依赖特定的结构假设,易受群组偏差影响,泛化性受限。
在这样的背景下,寻找一种无需额外监督、计算轻量且能提供细粒度信用分配 的方案,成为了 Agentic RL 领域的核心诉求。
2. 核心贡献 (Core Contributions)
本文从信息论和策略几何空间出发,提出了一种利用策略内生信息(响应级熵)来进行信用分配的创新框架,核心贡献如下:
理论突破:响应级熵动力学分析。 在 Fisher-Rao 度量下的策略单纯形中证明,自然梯度更新下的策略熵漂移,是由采样响应的优势函数 (Advantage) 和其相对惊奇度 (Relative Surprisal) 的交互作用共同决定的。这为使用不确定性作为内生信用信号提供了坚实的理论基石。算法创新:提出自适应熵调制 (AEM)。 提出了一种轻量级的免监督即插即用方法 AEM(Adaptive Entropy Modulation),利用基于熵推导出的不确定性代理指标来重新缩放响应级别的 Advantage。通过训练过程中正负样本比例的自然演变,AEM 能自适应地引导策略从早期的“探索 (Exploration)”平滑过渡到后期的“利用 (Exploitation)”。SOTA级别的实验验证: 在 ALFWorld、WebShop 及高难度的 SWE-bench-Verified 等多轮环境评测中,将 AEM 插入到 GRPO、DAPO、GSPO 等强基线中,在 1.5B 到 32B 不同参数规模下均取得显著提升(如在 ALFWorld 上使 GRPO 提升达 8.8%,在 SWE-bench 上使最先进的 DeepSWE 框架进一步提升 1.4%)。
3. 具体案例剖析 (Case Study / Example)
为了直观理解 AEM 的作用机制,我们来看一个 WebShop 网上购物场景 的多轮交互案例:
场景: 智能体需要购买一个特定规格的键盘。它经历了 5 个步骤:[Search] -> [Click Item 1] -> [Back] -> [Click Item 2] -> [Buy],最终购买成功(Reward=1)。
传统 GRPO 的做法: 由于最终拿到了 Reward=1,该轨迹的 Advantage $> 0$。GRPO 会将这 5 个步骤对应的动作全部“同等力度地”推高概率。但实际上,[Click Item 1] -> [Back] 是一个试错甚至冗余步骤,同等强化会导致策略学习到冗余动作,并且策略的“熵”会迅速崩塌(过早自信)。引入 AEM 的做法: AEM 会在训练时计算这 5 个步骤分别的“响应级熵(Response-level Entropy)”作为相对惊奇度(Surprisal Proxy)的代理。
如果在 [Click Item 2] -> [Buy] 这两个关键且正确的步骤上,模型本身也表现出了低熵(较确定),AEM 会计算出一个大于 1 的调制系数 $\alpha$,放大 它们的 Advantage(促进有效利用)。
相反,如果在早期的试错或探索阶段,AEM 会抑制对无用确信动作的过度梯度更新。
在遇到失败轨迹(Advantage $< 0$)时,AEM 会惩罚那些“低熵(极其自信)且错误”的响应,迫使模型恢复探索状态。
这种纯依赖模型内部生成的概率分布进行的动态加权,相当于为多轮任务隐式分配了“好步骤”和“坏步骤”的权重差异。
4. 方法论与技术实现 (Methodology & Implementation)
4.1 理论基础:响应级熵几何学 (Response-Level Entropy Geometry)
在 Agentic RL 中,环境状态的转移通常发生在智能体生成完整的一段回复 (Response) 之后,因此有效的动作粒度是响应级别而非 Token 级别。为此,作者定义了响应级惊奇度 $S(a_t | s_t) := -\log \pi_\theta(a_t | s_t)$ 以及响应级香农熵 $\mathcal{H}_{\text{resp}}(s_t)$。
基于自然梯度 (Natural Gradient) 理论,作者推导出了固定占据度下的熵漂移定理:
该公式揭示了一个深刻的结论:策略更新时的熵增减,完全由“采样响应的 Advantage $A(a,s)$” 与“相对惊奇度 $(S - \mathcal{H}_{\text{resp}})$”乘积的符号决定。
4.2 自适应熵调制机制 (AEM Mechanism)
既然内部熵反映了探索潜力,AEM 通过缩放 Advantage 来人为干预这一过程。由于真实状态下的确切熵值 $\mathcal{H}_{\text{resp}}(s_t)$ 难以精确计算,AEM 采用了一个基于 Group 的可预测代理并进行长度归一化:
1. 计算响应级熵代理:$\bar{\mathcal{H}}_{i,t} = \frac{1}{|S_{i,t}|} \sum_{\ell \in S_{i,t}} \mathcal{H}_\ell(a_t, s_t)$
4.3 隐式的探索-利用转变 (Exploration-Exploitation Transition)
AEM 能够自适应地产生 Phase Transition:
早期探索 (Exploration): 训练早期,多数交互失败,$A(a,s) < 0$。此时 AEM 加大对低惊奇度(模型自信但错误)样本的梯度更新,产生强大的“熵增”压力,强制模型打破现有次优置信区间,积极探索。后期利用 (Exploitation): 随着训练推进,成功样本增多,$A(a,s) > 0$。此时 AEM 放大对低惊奇度(自信且正确)样本的更新,产生“熵减”压力,推动策略快速收敛。
5. 实验设置与结论分析 (Experiments & Results)
评测基准:
ALFWorld: 评估基于文本的具身决策。WebShop: 评估基于 Web 导航的电商购物 Agent。SWE-bench-Verified: 现实世界的软件工程长视距验证基准,难度极高。
实验结果亮点:
显著的性能提升: 在 Qwen2.5-1.5B/7B 的测试中,GRPO+AEM 在 ALFWorld 上相较于基础 GRPO 取得了 8.8% / 5.7% 的绝对提升,在 WebShop 上取得了 5.6% / 4.6% 的绝对提升。对于当前开源最优长上下文强化方法 DAPO,AEM 依然能够形成有效的补充。冲击高难 SWE-bench: 将 AEM 无缝集成至顶尖开源代码智能体训练框架 DeepSWE 中 (模型 Qwen3-32B),成功将成功率从 42.3% 进一步推高至 43.7%,证明了该方法在产业级长链路开发任务上的泛化与有效性。缓解过早熵塌陷 (Mitigating Premature Entropy Collapse): 作者分析了训练过程的熵值曲线,基础 GRPO 在早期会遭遇“熵崩塌”,导致陷入局部最优。而引入 AEM 后,早期的探索多样性得到了明显的保护,后期曲线亦能稳定收敛。消融实验与鲁棒性验证: 实验证明,如果把调制系数 $\alpha$ 随机打乱(shuffle)或者反向映射(reverse),性能会大幅回落甚至不如 Baseline。这意味着 AEM 有效的关键在于“熵信号必须准确分配给它所对应的响应”,其方向的正确性至关重要。
6. 关键技术亮点分析 (Key Highlights & Takeaways)
“零开销”细粒度信用分配: 最大的工业价值在于,AEM 完全无需引入任何外部监督模型 (免去 PRM 的显存开销),且不需要额外的网络 Forward Pass 。在计算旧策略对数概率 (old-policy log-probs) 时顺手就能把熵聚合计算出来。其实际计算开销在整个 GRPO Pipeline 中占比仅有 1.1% 。粒度对齐:从 Token 升维至 Response。 过去的强化学习方法(如 PPO)多在 Token 级别做限制,这在自然语言生成中容易失真(例如 Token 预测中的强制词法搭配)。AEM 将“行动 (Action)”的定义上提至 Response 级,这完美契合了 LLM 作为智能体时“思考并输出完整动作 -> 环境给出状态反馈”的马尔可夫决策过程 (MDP) 语义。优美的理论机制: 大部分工程化 RL Tricks 是启发式的,但 AEM 基于 Fisher-Rao 流形对齐了自然梯度下的信息几何动力学,数学推导严密。这种“基于相对确定性的内生调制”是对 Actor-Critic 等重架构体系的一种极其优美的“轻量化”平替。
总结: AEM 是一项“小改动、大收益”的卓越工作。在对齐税高昂、显存吃紧的大模型后训练时代,这套轻量级的自适应熵调制算法无疑是进一步深挖长思考 (Long-CoT) 和多轮智能体 (Multi-turn Agent) 能力上限的一把利器。