Superintelligent Retrieval Agent: The Next Frontier of Information Retrieval
SIRA:信息检索的下一个前沿——超智能检索Agent
作者:Zeyu Yang, Qi Ma, Jason Chen, Anshumali Shrivastava
机构:Meta Superintelligence Labs, Rice University
📄 查看 ArXiv 原文
研究背景与痛点 (Background & Pain Points)
在大模型和 RAG(Retrieval-Augmented Generation)时代,信息检索系统正逐渐演变为基于自然语言对话和多轮问答的交互范式。然而,当前的搜索 Agent 和检索基础架构面临着根本性的不匹配与痛点:
- Agent 成了“盲人摸象”的新手: 现有的多轮检索 Agent 往往把检索动作当成黑盒。Agent 发出查询后,必须“阅读”召回的片段来积累上下文,然后不断调整改写。这种 retrieval-context advantage 使得系统高度依赖大模型的多轮长上下文处理,延迟极高且具盲目性。专家搜索并非如此,领域专家在看到文档之前,就已经能在脑海中预判高概率命中的“核心术语”。
- Dense Retrieval 的局限性: Embedding 检索受限于单向量表达,难以处理复杂约束意图,且严重依赖领域内监督数据。随着 AI Summary 普及,点击信号正变得稀疏而有偏。
- 被低估的传统 Lexical Retrieval: BM25 这类稀疏词汇检索高度透明、可审计,并能通过 IDF 敏锐奖励高区分度术语。它的问题是 Vocabulary Gap,而 LLM 的参数化知识正好能弥补这一点。
核心贡献 (Core Contributions)
本作定义了检索领域的“超智能”:将传统繁冗的多轮探索式搜索,压缩成单次、具备领域判别性的受控检索动作。核心贡献如下:
- 提出 SIRA: 一种 training-free、无需相关性标签的新型 Agentic Retrieval 框架,用冻结 LLM 充当 BM25 的“外脑控制器”。
- 双端词汇增强: 同时从语料端离线增强与查询端在线增强两侧,缓解 Vocabulary Gap。
- 引入 DF Filter: 让 LLM 生成的扩展词必须满足在语料中真实存在、且不过于高频,从而抑制 hallucinated query expansion。
- 性能显著领先: 在 BEIR 等多组 benchmark 上,零样本设置下全面超越 BM25、E5、SPLADE 与多轮 RL 搜索 Agent。
具体案例剖析 (Case Study)
示例查询:What is the name of the researcher who discovered the theory of relativity?
- 普通 Agent: 直接搜“researcher / theory of relativity”,往往先召回泛化科普文,再靠多轮重写补救。
- SIRA:
- 先由 LLM 生成 expected-response sketch,例如 patent office、photoelectric effect、spacetime、Nobel Prize in Physics 1921 等答案周边高区分词。
- 再用 DF Filter 过滤掉 DF=0 的幻觉词,以及过于泛化的高频词。
- 最后将原 query 与过滤后的扩展词组合为加权 BM25 检索,一次性更大概率命中包含 Einstein 的目标文档。
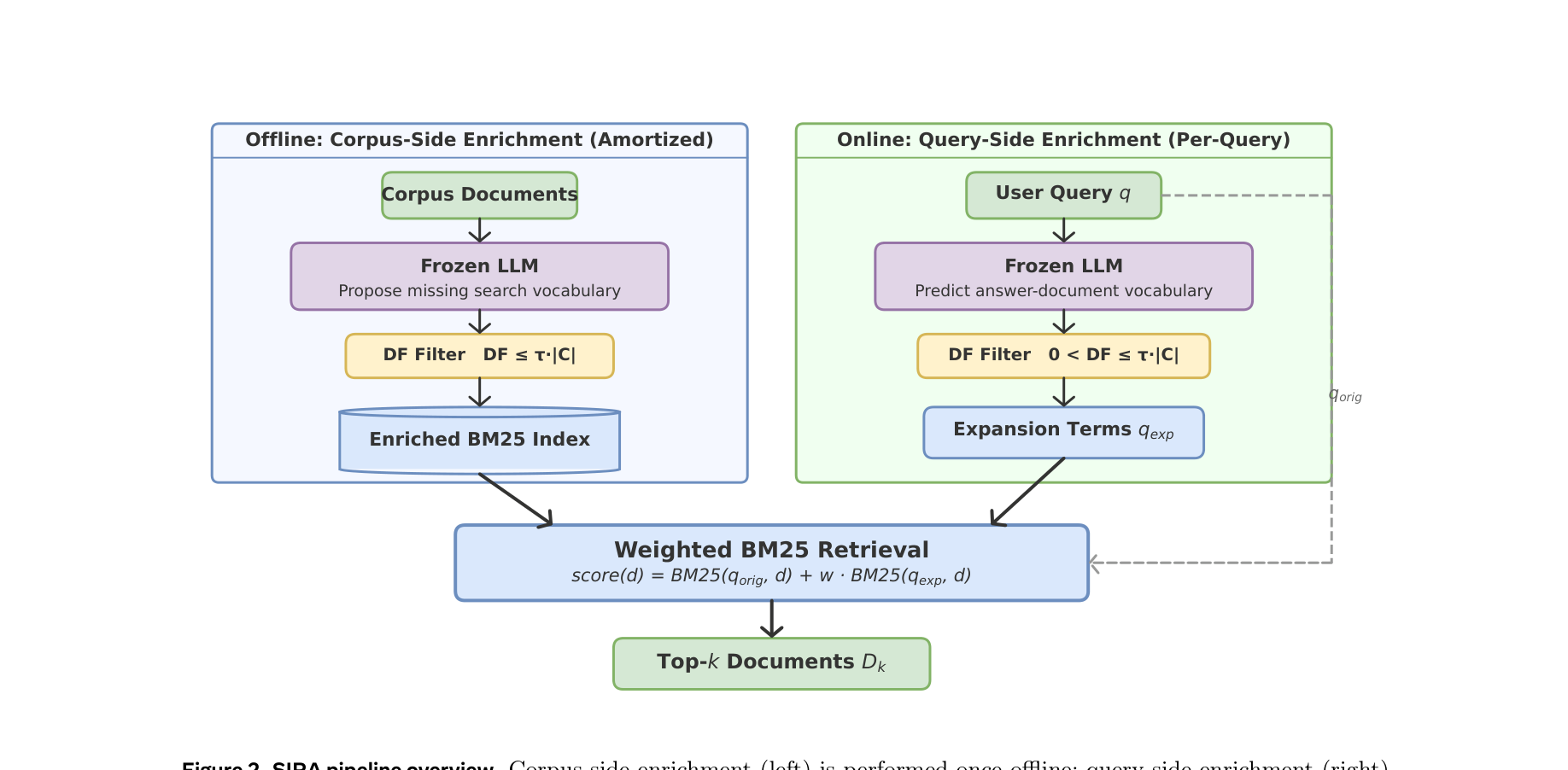 图注:SIRA 流水线架构概览。左侧为离线的语料库端增强,右侧为在线的查询端增强,二者最终汇合到一次加权 BM25 检索。
图注:SIRA 流水线架构概览。左侧为离线的语料库端增强,右侧为在线的查询端增强,二者最终汇合到一次加权 BM25 检索。
方法论与技术实现 (Methodology)
1. 语料端离线增强
冻结的 LLM 读取语料库中的文档,预测用户可能使用但文档中缺失的搜索词(同义词、缩写、别名、对立观点词等)。所有候选词都要通过 DF 过滤,只保留满足 $DF \le \tau \cdot |C|$ 的短语,再注入增强版 BM25 倒排索引。
2. 查询端在线增强
针对用户查询 $q_{orig}$,LLM 生成 expected-response sketch,再通过相同的 DF 过滤器校验,要求这些扩展词既不能太泛化,也必须在当前索引中真实存在。
3. 加权 BM25 重组
最终评分形式为:
$\text{score}(d) = \text{BM25}(q_{orig}, d) + w \cdot \text{BM25}(q_{exp}, d)$
这样进入 $q_{exp}$ 的词往往具备高 IDF,从而在排序时主导区分真正相关文档与 confusers。
实验设置与结论分析 (Experiments & Results)
作者在 BEIR 10 个数据集上进行评估,对比 BM25、E5、SPLADE、HyDE 以及各类多轮搜索 Agent。SIRA 在零监督设置下平均 Recall@10 达到 0.691,显著优于 E5 的 0.648、SPLADE 的 0.625 与 BM25 的 0.530。
在 NQ 和 HotpotQA 等下游 QA 任务中,SIRA 作为单轮 Retriever,其 Top-10 answer coverage 甚至超过部分复杂 Agent 系统的最终 QA 准确率,说明“高质量单发检索”本身就可能比低质量多轮搜索更值钱。
关键技术亮点分析 (Key Technical Highlights)
- Interaction-as-Programming: 不是让 LLM 读取搜索结果,而是让 LLM 直接“编程”底层 BM25。
- 成本与可解释性兼得: 无需 dense vector index,无需 ANN 后端,完全基于成熟倒排索引即可获得高性能。
- 挑战多轮 Agent 范式: 如果一次 lexical action 足够专家化,未必需要多轮搜索试错。
StraTA: Incentivizing Agentic Reinforcement Learning with Strategic Trajectory Abstraction
StraTA:通过战略轨迹抽象激励智能体强化学习
📝 作者:Xiangyuan Xue, Yifan Zhou, Zidong Wang, Shengji Tang, Philip Torr, Wanli Ouyang, Lei Bai, Zhenfei Yin
🏫 机构:香港中文大学、上海人工智能实验室、乔治亚大学、牛津大学、深圳循环区研究院等
📄 查看 ArXiv 原文
研究背景与痛点
现有 Agentic RL 多数仍是纯反应式策略:在每个时间步只根据当前状态直接生成动作。这会导致短视探索、回溯增多以及前后行为不一致。同时,长轨迹任务的奖励往往高度稀疏、严重延迟,信用分配极难。
StraTA 的直觉是:像人类解决复杂问题一样,模型应该先显式产出一段高层 Strategy,再在其约束下执行细粒度 Action,并在事后复盘策略与执行的一致性。
核心贡献
- 显式战略轨迹抽象: 让模型先基于初始状态生成自然语言全局策略 $z$,再在后续每一步动作生成时将其作为条件。
- 层次化 GRPO: 在策略层与动作层上构造两级采样与优化结构。
- 多样性策略采样 + 自我评判: 用最远点采样鼓励策略探索,用批判性自我判断为不遵循策略且无助于完成任务的步骤施加惩罚。
- 实证效果强: 在 ALFWorld、WebShop、SciWorld 上明显领先多种开源 RL baseline 与若干闭源模型。
具体案例剖析
在 SciWorld 中,模型先生成“先开 hallway door、观察环境、再去 outside 比较动物寿命”的全局策略,后续诸如 open、goto、focus 等动作都围绕该策略展开。若 rollout 中存在偏离路线的无效动作,训练阶段的 self-judgment 会将其标记为惩罚目标,从而改善 credit assignment。
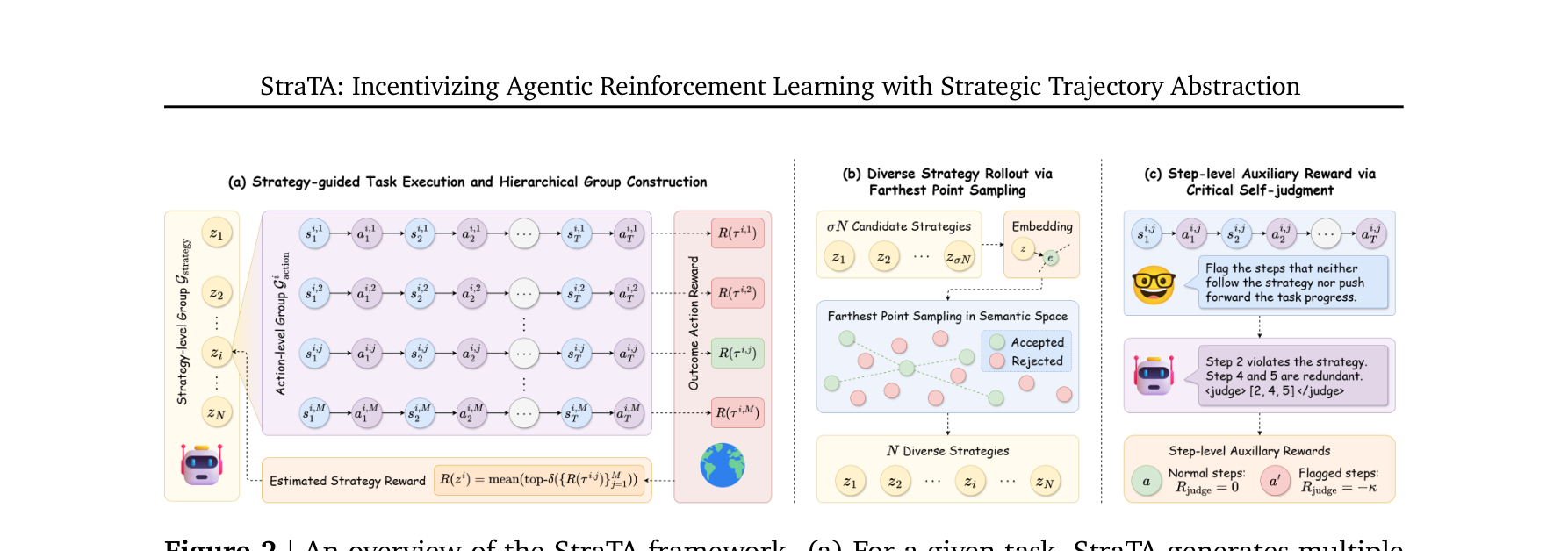 图注:StraTA 框架概览。左图展示层级 GRPO 组构建,中图展示策略多样性采样,右图展示基于自我判断的步级辅助惩罚。
图注:StraTA 框架概览。左图展示层级 GRPO 组构建,中图展示策略多样性采样,右图展示基于自我判断的步级辅助惩罚。
方法论与技术实现
在初始状态 $s_1$ 上先生成文本策略 $z \sim \pi_\theta(\cdot \mid s_1)$,后续动作按 $a_t \sim \pi_\theta(\cdot \mid z, s_t)$ 生成。StraTA 对每个任务先采样多个策略,再在每个策略下采样多条轨迹。
为了评估策略层质量,作者没有直接平均其下所有 rollout 回报,而是对其中 top-$\delta$ 的高质量 rollout 取均值,从而近似表示该策略的上界潜力:
$ R(z^i) = \text{mean}(\text{top-}\delta (\{R(\tau^{i,j})\}_{j=1}^M)) $
同时引入最远点采样选择语义上最分散的策略,并让模型在轨迹结束后判断哪些步骤既没遵守全局策略、也没推动任务进度,再对这些步施加辅助惩罚。
实验设置与结论分析
在 7B 级别,StraTA 在 ALFWorld 达到 93.1%,WebShop 达到 84.2%,SciWorld 达到 63.5%,均显著超过 Vanilla GRPO 和多种强基线。加入 Diverse + Judgment 后,训练收敛更快,最终性能更高。
关键技术亮点分析
- Language as Latent Abstraction: 直接把自然语言当作高层策略表示,降低了分层 RL 的抽象定义难度。
- Top-$\delta$ 保护高潜策略: 避免优质策略被早期低质量动作执行噪声误伤。
- 闭环自举: 规划、执行、复盘均由同一 LLM 体系完成,不依赖额外 Critic 网络。
基本信息
英文标题:Can RL Teach Long-Horizon Reasoning to LLMs? Expressiveness Is Key
中文标题:RL 能教会大语言模型长程推理吗?逻辑表达能力是关键
作者:Tianle Wang, Zhaoyang Wang, Guangchen Lan, Xinpeng Wei, Sipeng Zhang, Guanwen Qiu, Abulhair Saparov
机构:普渡大学、UNC、Georgia Tech、UCSD
📄 查看 ArXiv 原文
研究背景与核心痛点
RLVR 正成为提升 LLM 复杂推理能力的关键后训练范式,但真实数学/代码数据虽然可自动验证,却难以精细控制“推理深度”与“逻辑表达能力”。这使得我们很难系统回答:随着 horizon 变深、表达能力变强,训练成本究竟如何增长。
核心贡献
- 提出 SCALELOGIC: 纯合成、无限可扩展的逻辑推理后训练环境,将任务难度解耦为推理深度 $D$ 与逻辑表达能力。
- 发现幂律: 达到固定准确率所需 RL 步数与深度呈幂律关系 $T \propto D^\gamma$。
- 证明表达能力决定 scaling 效率: 随着逻辑从 implication-only 升级到含 quantification 的一阶逻辑,$\gamma$ 明显变大。
- 迁移有效: 在更强表达能力的合成逻辑上 RL 训练,可显著提升数学与科学 benchmark 表现。
具体案例剖析
论文展示了一个典型差异:未经 RL 的模型在对数方程题中只考虑“判别式为 0”这一浅层情况,直接得出答案 2;而经 SCALELOGIC 强化后的模型会继续检查定义域与根分布,显式展开分支推理,最终得出正确答案 501。这个案例非常直观地证明:模型学到的是“补全逻辑树与验证遗漏分支”的能力,而不是某类题目的模板。
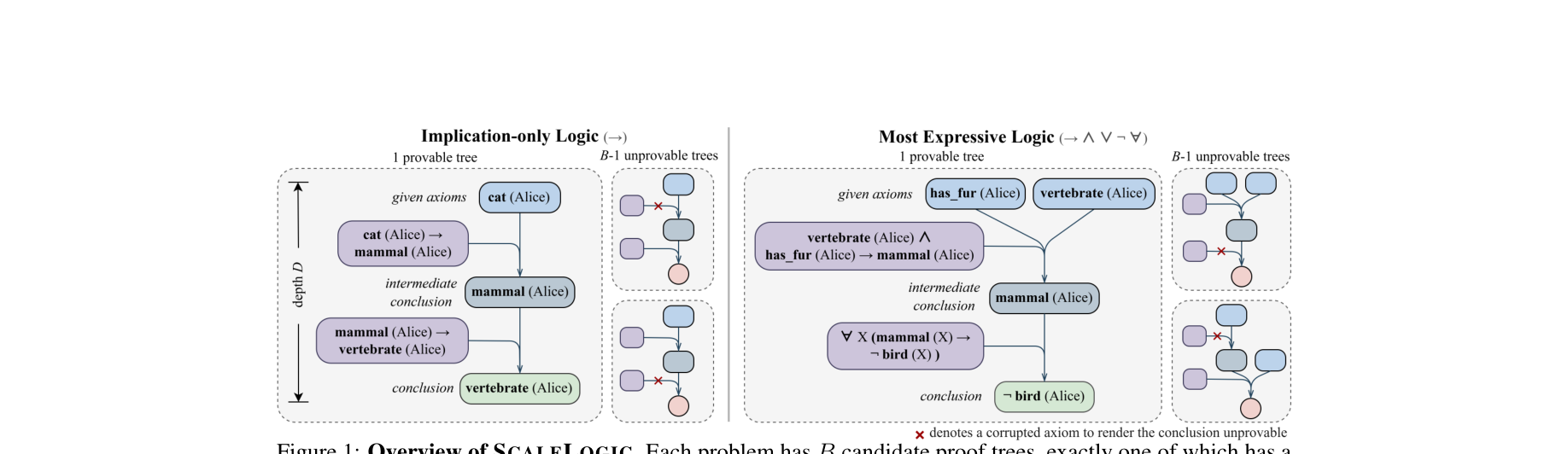 图注:SCALELOGIC 框架图。通过后向构造生成唯一可验证证明树,并系统控制逻辑表达能力与树深度。
图注:SCALELOGIC 框架图。通过后向构造生成唯一可验证证明树,并系统控制逻辑表达能力与树深度。
方法论与技术实现
作者使用 backward construction:从候选结论反向生成规则树,再对错误选项做轻微破坏,确保每道题具有唯一正确推导路径。框架支持 implication、conjunction、negation、disjunction、quantification 五级表达能力。
强化学习部分采用基于 GRPO/DAPO 的设置,仅在最终答案正确时给出二元稀疏奖励。结果显示,长程推理的训练成本随深度近似满足幂律。
实验设置与结论分析
在 Qwen3-4B / 8B 上,作者发现当逻辑表达能力增强时,幂律指数 $\gamma$ 从接近线性增长一路提升到明显超线性。使用课程学习后,可显著降低训练成本曲线的陡峭程度。同时,这些在合成逻辑上得到的能力能稳定迁移到 MATH500、AIME、GPQA 等真实 benchmark。
核心技术亮点与启发
- 合成数据不是量的问题,而是表达能力的问题。
- 课程学习在长 horizon RL 中几乎是必选项。
- Backward construction 非常适合生成高质量 hard negatives。
ROSE: Rollout On Serving GPUs via Cooperative Elasticity for Agentic RL
ROSE:通过协作弹性在 Serving GPU 上加速 Agentic RL 的 Rollout
作者:Wei Gao, Yuheng Zhao, Tianyuan Wu 等
机构:香港科技大学、阿里巴巴集团
📄 查看 ArXiv 原文
研究背景与核心痛点
Agentic RL 的 rollout 通常占到总体 wall-clock 的大头,而且轨迹时长分布存在明显 long-tail。静态分配 GPU 会造成大量等待;而 spot/serverless 弹性扩容又会引入冷启动、容器重拉与模型重载的额外成本。另一方面,Serving 集群为了应对流量峰值,平时往往长期闲置。
核心贡献
- Cooperative Elasticity: 在不破坏 Serving SLO 的前提下,动态借用线上 Serving GPU 的闲置算力与显存给 RL rollout 使用。
- 稀疏权重增量传输: 发现 RL 对齐阶段模型参数更新高度稀疏,用稀疏差分显著降低跨集群同步时间。
- 异构混部与页级显存重映射: 基于 CUDA VMM 实现无需重启的显存页重分配。
具体案例剖析
在训练集群与线上集群分离的场景中,ROSE 会在平峰时把大量 rollout 调度到 Serving GPU 上;一旦线上突发流量,系统立即回收 rollout 的 KVC 预算,把显存页归还给 Serving 模型。被驱逐的 rollout 任务再路由回训练集群继续执行,保证用户侧 TTFT/TPOT 不被拖垮。
方法论与技术实现
ROSE 通过双 SLO 准入控制,在 TTFT 与 TPOT 的 slack 允许范围内插入 rollout token 计算。对显存管理,利用 CUDA VMM 维护 Serving 与 Rollout 各自的虚拟地址空间,并按页重映射底层物理显存。
在跨集群同步中,作者不直接传全量权重,而是传递 $\Delta W_t = W_t - W_{t-1}$ 的稀疏表示,再在目标侧恢复,极大降低跨机房带宽压力。
实验设置与结论分析
在 Qwen3-8B 与 Qwen3-32B 的 Agentic RL 设置下,ROSE 相比固定资源框架和若干弹性基线,在吞吐上达到 1.2x–3.3x 的提升,同时能更稳定满足 Serving 端的 P99 SLO 约束。
关键技术亮点分析
- 把“闲置 Serving 资源”变成 RL rollout 的弹性池。
- 对齐阶段权重更新高度稀疏,是非常有价值的工程发现。
- 真正面向 Agentic 负载特征做系统设计,而非套用通用混部模板。
SkillOS: 智能体自我进化的技能库精选强化学习框架
Title: SkillOS: Learning Skill Curation for Self-Evolving Agents
作者: Siru Ouyang, Jun Yan, Yanfei Chen, Rujun Han, Zifeng Wang, 等
机构: UIUC, Google Cloud AI Research, MIT
📄 查看 ArXiv 原文
研究背景与痛点
多数 LLM Agent 仍是一次性问题求解器,无法真正从历史任务中积累可复用技能。现有记忆管理方法要么依赖人工编写,要么依赖启发式规则,难以在开放域长期任务流中高质量地进行技能插入、更新与删除。
核心贡献
- 双智能体解耦: 冻结 Executor,只训练 Skill Curator 来管理外部 SkillRepo。
- Grouped Task Streams: 将具潜在技能依赖的任务串成流,用前序任务的技能更新去影响后续任务表现,获得更合理的 delayed reward。
- 复合奖励: 综合任务表现、函数调用合法性、内容压缩率与外部 judge 评分,形成更稳定的训练信号。
具体案例剖析
在 AIME 类数学任务中,SkillOS 生成的技能不再只是泛泛而谈的文字,而是会产出带 workflow、约束条件和示例的 procedural knowledge;在 ALFWorld 中,它能从历史经验中总结出“先取目标物、再去光源处检查”这类真正可复用的行动策略。
方法论与技术实现
SkillOS 将每个技能组织为 SKILL.md 风格文件。Curator 的动作空间被约束为 insert_skill、update_skill、delete_skill 三类操作。训练时,以任务组为单位顺序执行,使早期任务产生的技能能够影响后续任务。
整体奖励可表示为:
$r = r^{task} + \lambda_f r^{fc} + \lambda_u r^{cnt} + \lambda_c r^{comp}$
其中任务成败是核心信号,另辅以函数调用格式、内容压缩与外部 judge 评分,避免模型只是把轨迹原文塞进记忆库。
实验设置与结论分析
在 ALFWorld、WebShop 及数学推理任务上,SkillOS 一致优于无记忆和多种 memory baseline,同时还显著降低交互步数。更有价值的是:训练出的 Curator 可以迁移服务于更强的 Executor,显示出明显的跨执行器泛化能力。
关键技术亮点分析
- 从“记事本”进化为“知识库”。
- 元技能会在 RL 训练中自然涌现。
- Executor / Curator 解耦非常利于工程落地与未来升级。