TADI: Tool-Augmented Drilling Intelligence via Agentic LLM Orchestration over Heterogeneous Wellsite Data
中文标题:TADI:基于智能体 LLM 编排异构井场数据的工具增强钻井智能系统
作者:Rong Lu
机构:基于 Equinor Volve 开源井场数据的独立研究
📄 查看 ArXiv 原文
研究背景与痛点
这篇论文瞄准的是一个非常典型、也非常“硬”的工业 Agent 场景:钻井作业会持续产生异构数据,包括 DDR 日报、WITSML 传感器、高频时序、泥浆属性、测井结果等。传统 Dashboard 善于看结构化传感器,但基本吃不下自由文本叙述;通用 RAG 又很难把具体深度、日期、操作事件和文本证据绑定在一起,最终很容易产生“听起来合理但不可追溯”的回答。
作者的核心判断很务实:在这种高风险工业领域,LLM 不能只做被动总结器,而必须成为能规划工具调用、汇总跨模态证据、最终给出证据链的 Agent。否则,无论模型多强,都无法满足工程现场对可解释性和证据引用的要求。
核心贡献
- 提出 TADI 双存储架构:DuckDB 负责结构化聚合,ChromaDB 负责语义检索。
- 没有让 LLM 直接自由写 SQL,而是封装成 12 个钻井专家工具,由 LLM 负责编排。
- 提出 Evidence Grounding Score (EGS),要求回答包含测量值、DDR 原文引述和结构化段落。
- 展示一种 framework-free 的 Agent 工程范式:不用 LangChain/LlamaIndex,主要依靠系统提示词与函数调用实现。
具体案例剖析
案例 1:钻井阶段识别。 用户询问某口井的主要钻井阶段及其证据。TADI 先调用结构化工具识别 26''、17.5''、8.5'' 等阶段,再去 DDR 中补齐叙述证据,最终不仅给出阶段边界和耗时,还能引用诸如 “Observed 30 tons overpull.” 之类的一线现场记录。
案例 2:故障诊断。 用户询问作业中的关键问题和成因。系统先在结构化活动日志里扫描 NPT / 故障事件,再回查对应日报,并联动泥浆密度、扭矩等统计量。输出不是泛泛的“可能有设备问题”,而是能定位到具体事件,并排除无关变量。
这两个例子说明:在工业 Agent 中,价值不在“模型会不会说”,而在“模型能不能把不同模态的证据串成一条审计链”。
方法论与技术实现
TADI 本质上是一个有界工具调用过程。设工具集为 $\mathcal{T}=\{t_1,\dots,t_n\}$,在第 $i$ 步,Agent 根据用户问题 $q$、系统提示 $s$ 和当前已收集证据 $E_{1:i-1}$ 选择动作:
$(t_{j_i}, a_i)=\pi_\theta(q,s,E_{1:i-1})$
系统显式限制调用预算,从而迫使模型进行规划而不是盲目试探。更关键的是,领域知识被沉淀在工具里,而不是寄希望于 LLM 现场“发明算法”。例如某些作业难度指标直接在代码中计算,如:
$D_{section}=z(\text{WOB})+z(\text{Torque})-z(\text{ROP})$
这种“代码承载专业逻辑,LLM 负责编排”的设计,在 B 端高约束场景里非常靠谱。
实验设置与结论分析
论文的亮点不在传统 benchmark,而在工程化评估。作者用 130 个领域问题构造压力测试,并通过 EGS 衡量输出是否真正 grounded。EGS 的核心思想可以写成:
$\text{EGS}(\hat y)=\frac{1}{3}(\mathbb{1}[\text{measurement}]+\mathbb{1}[\text{quote}]+\frac{|sections|}{6})$
也就是说,回答不仅要“答对”,还要同时有数字、有原文证据、有结构。论文还做了几组有代表性的消融:如果只保留 SQL 接口,复杂问题很容易耗尽预算;如果取消强制交叉引用,系统就会退化成只看结构化数据的“证据单一化”模式。
关键技术亮点分析
- 这篇文章再次说明,垂直 Agent 的瓶颈往往不是模型,而是工具设计。
- framework-free 的实现方式很值得抄:减少抽象层,调试和审计都更直接。
- 强制 cross-reference 很关键,它解决的是工业界真正关心的“我为什么要信你”。
AgentReputation: A Decentralized Agentic AI Reputation Framework
中文标题:AgentReputation:去中心化智能体 AI 声誉框架
作者:Mohd Sameen Chishti, Damilare Peter Oyinloye, Jingyue Li
机构:Norwegian University of Science and Technology
📄 查看 ArXiv 原文
研究背景与痛点
随着 Agent 从 demo 走向真实软件工程、安全审计、任务外包市场,一个核心问题开始变得尖锐:我们如何信任一个去中心化 Agent?传统单分数评级几乎没用,因为 Debug 能力不等于安全审计能力,自动化测试通过也不等于专家人工审查通过。
论文把这个问题总结为“信任不可能三角”:Agent 会为评测钻空子、上下文不同导致声誉不能跨任务迁移、不同验证机制的置信度又完全不同。这个问题很像 LLM Eval 里的 leaderboard 幻觉,只不过这里进一步进入了经济系统和权限分发层。
核心贡献
- 提出基于证据的 Agent 声誉框架,而不是简单历史评分。
- 用 Reputation Cards 隔离不同领域与任务类型的声誉,避免上下文坍塌。
- 把声誉直接接到策略引擎,用于准入控制、质押要求和惩罚机制。
具体案例剖析
论文举了一个非常直观的例子:Agent α 做过 500 个 debug 任务,自动化测试通过率很高;Agent β 虽然 debug 记录少,但做过多个安全审计任务,而且验证方式是专家人工审查。现在系统来了一个处理千万美元资产的 DeFi 合约漏洞分析任务。
传统单分数机制下,α 可能分更高;AgentReputation 下,系统会先只看“安全审计”相关声誉卡,再比较验证强度,并把高风险任务映射为更高质押要求。结果是 β 更可信,α 需要付出更高风险溢价。这种按上下文与验证强度重定价的思路,非常适合未来 agent marketplace。
方法论与技术实现
论文采用三层架构:功能层负责 Task Owner、Agent 和 Verifier 交互;声誉服务层负责计算 Reputation Cards 与 Policy Engine;区块链/存储层负责不可篡改记录。单次交互被编码为事件元组:
$e=\langle agent, task, regime, outcome, strength, timestamp, integrity\rangle$
这里的 strength 用来区分静态扫描、自动执行测试、专家审查等验证方式的置信度。策略引擎并不直接吃一个总分,而是消费按上下文隔离后的 reputation card,再决定 access gating、stake、slashing 等动作。
实验设置与结论分析
这篇更偏框架和系统设计,没有标准 benchmark 式量化结果。它真正的价值是提出了未来去中心化 Agent 生态必须解决的开放问题:验证语义的机器可读表示、验证强度的量化、冷启动、以及隐私和可验证性的权衡。
如果你关心的是 LLM Agent 在真实世界中的“可信协作基础设施”,这篇论文的重要性其实不低,因为它把评测、市场机制与权限控制第一次系统地绑在了一起。
关键技术亮点分析
- Contextual Reputation Cards 很有启发性,适合借鉴到企业内部 Agent 权限体系。
- “验证强度”这个概念很重要,能把不同级别的评审质量纳入统一框架。
- 它展示了 Web3/区块链在 Agent 时代一个更靠谱的落点:作为可信记录与仲裁层,而不是炒概念。
Minimal, Local, Causal Explanations for Jailbreak Success in Large Language Models
中文标题:大语言模型越狱成功的极简、局部、因果解释
作者:Shubham Kumar, Narendra Ahuja
机构:University of Illinois Urbana-Champaign
📄 查看 ArXiv 原文
研究背景与痛点
越狱攻击一直是 alignment 圈里最烦人的问题之一。已有很多 mechanistic interpretability 工作试图解释“为什么模型会被越狱”,但常见问题是:解释过于全局、缺少样本级因果性、而且需要干预太多特征,最后解释虽然高级,却很难指导防御。
这篇论文希望找到一种真正局部、真正可验证、真正极简的解释——最好只 patch 少数几个特征,就能把越狱成功重新打回拒绝输出。
核心贡献
- 提出 LOCA(Local, Causal)算法,用 SAE 特征找最小因果解释。
- 在 Llama-3.1-8B-Instruct 上,平均只需 6 个左右 patch 就能恢复拒绝。
- 揭示不同层里关键 token 的位置迁移:前层偏 instruction token,后层更集中在 chat template / punctuation 等结构 token。
具体案例剖析
一个典型 case 是 AutoDAN 越狱。原始请求“如何非法获取枪支”会被模型拒绝;加上 AutoDAN 风格的开发者模式包装后,模型开始输出危险内容。
LOCA 发现,在某些层只要做两个关键 patch:一是增强与“有害内容警报”相关的特征,二是抑制与“代码生成上下文”相关的特征,模型就会重新拒绝。这种解释非常漂亮,因为它不是泛泛地说“安全性被压低了”,而是明确指出:越狱是通过压制警报并伪装成 harmless coding context 实现的。
方法论与技术实现
LOCA 的核心是把越狱样本 $x_j$ 的内部表示逐步拉向原始拒绝样本 $x_o$。为了避免穷举所有 token 与 SAE 特征,作者对 KL 散度使用一阶近似,计算每个方向的收益:
$d(i,\mathbf{v})=\left[\nabla_{\mathbf{h}_{j,i}} KL(\mathbf{p}_o\|\mathbf{p}_j)^T\mathbf{v}\right]\left(\mathbf{h}_{o,\mathcal{M}(i)}-\mathbf{h}_{j,i}\right)^T\mathbf{v}$
然后算法不是一次选 Top-K,而是迭代 patch:每做一步,就重新前向传播,更新后续候选。这一点很关键,因为特征之间存在强交互。
实验设置与结论分析
论文在 Gemma-2-2B-IT 和 Llama-3.1-8B-Instruct 上测试,使用 HarmBench 挑选高质量越狱成功样本。对比基线方法后,LOCA 在最少 patch 数和恢复拒绝率上都明显领先。
对从业者来说,最有价值的不是“又一个更高分”,而是它给出了能落到 token / 特征级别的解释,直接为防御探针、结构化干预和表示级监控提供了抓手。
关键技术亮点分析
- 它证明了 token-specific 视角比 token-averaged 的梯度分析有效得多。
- 它揭示了模型内部“前层理解内容、后层把判决汇总到结构 token”的有趣模式。
- patching 相比 steering 更稳健,因为它更接近数据流形内的干预。
Are Tools All We Need? Unveiling the Tool-Use Tax in LLM Agents
中文标题:工具真的是我们需要的一切吗?LLM Agent 的工具使用税
作者:Kaituo Zhang, Zhen Xiong, Mingyu Zhong, Zhimeng Jiang, Zhouyuan Yuan, Zhecheng Li, Ying Lin
机构:University of Houston, USC, NYU, Texas A&M, UC San Diego
📄 查看 ArXiv 原文
研究背景与痛点
Tool-use 几乎已经成了 Agent 领域的政治正确:遇到复杂问题就上 calculator、search、API。但这篇论文问了一个很扎心的问题——在有语义干扰的真实环境里,工具调用真的一定比原生 CoT 更好吗?
作者发现,答案并不乐观。很多任务里,模型本来靠 CoT 就能做对;一旦进入函数调用协议,反而会因为 JSON 格式、轮次切换、状态机控制等额外复杂性而出错。这种额外成本被作者称为 Tool-Use Tax。
核心贡献
- 提出 Tool-Use Tax 视角,用 native CoT 作为真正基线。
- 设计 Factorized Intervention Framework,把损失拆成格式成本、协议开销、执行收益三部分。
- 提出 G-STEP 门控机制,在函数调用流程即将结束时判断该 commit 还是继续计算。
具体案例剖析
论文在 GSM8K 上构造语义干扰:例如题目问 Natalia 四月卖了 48 个夹子、五月卖了一半,总共多少;同时插入无关干扰“Alex 六月计划卖 5 个”。
原生 CoT 往往能忽略这个数字,正确算出 72;进入工具调用后,模型可能把“5”错误带入最后一步,算成 77。这个案例很说明问题:工具没有出错,错的是“为了用工具而重组推理流程”这件事本身。
方法论与技术实现
论文定义了一条很有启发的退化链:
$\text{CoT}\xrightarrow{\Delta_{sty}}\text{FCStyle}\xrightarrow{\Delta_{frc}}\text{NoopTool}\xrightarrow{\Delta_{cmp}}\text{Full}$
于是完整性能差可以分解为:
$Acc(Full)-Acc(CoT)=\Delta_{cmp}+\Delta_{frc}+\Delta_{sty}$
其中 $\Delta_{sty}$ 是 function calling 格式本身带来的损失,$\Delta_{frc}$ 是多轮协议开销,$\Delta_{cmp}$ 才是真正工具执行带来的收益。这个分解非常适合企业 Agent 调试。
实验设置与结论分析
作者在 GSM8K 与 HotpotQA 等任务上测试多个 FC 模型,发现最反直觉的一点是:在语义干扰环境中,Agent-Full 往往明显弱于 NoTool-CoT。工具本身当然能带来正收益,但协议成本太高,最后总账反而亏损。
论文还发现一个非常现实的现象:所谓“工具帮忙做对”的样本里,大多数其实模型原本不用工具也能做对。这说明很多场景的 tool augmentation ROI 其实是负的。
关键技术亮点分析
- 这篇文章对 Agent 工程特别重要,因为它提醒大家:不要默认所有任务都该进 tool loop。
- Factorized Intervention Framework 是极实用的诊断方法,可直接迁移到生产系统评估。
- G-STEP 体现了一个重要方向:在推理过程中动态判断“是否值得继续工具调用”。
TUR-DPO: Topology- and Uncertainty-Aware Direct Preference Optimization
中文标题:TUR-DPO:拓扑与不确定性感知的直接偏好优化
作者:Abdulhady Abas, Fatemeh Daneshfar, Seyedali Mirjalili, Mourad Oussalah
机构:University of Kurdistan, Torrens University, Óbuda University, University of Oulu
📄 查看 ArXiv 原文
研究背景与痛点
DPO 已经是当前偏好对齐的主力方法之一,因为它比 PPO-RLHF 简洁得多。但 vanilla DPO 有两个老问题:一是把整条回答当成扁平序列处理,无法区分“答案对但推理结构烂”和“答案错但过程有价值”;二是面对噪声偏好数据时太“轻信”,容易被脏数据带偏。
这篇论文试图给 DPO 补上结构感知与不确定性感知两块短板,目标是在不把训练系统重新变成 PPO 巨兽的前提下,提升推理型任务的对齐质量。
核心贡献
- 把回答解析成子主张与依赖关系构成的推理拓扑图。
- 将语义忠实度、拓扑连贯性和不确定性组合为 shaped reward,作为 DPO 的 margin 信号。
- 通过实例加权降低高不确定性 / 高噪声偏好对的训练影响。
具体案例剖析
想象一道多步数学题:候选答案 $y^+$ 最终结果对了,但中间跳了关键步骤;另一个回答 $y^-$ 过程扎实,但最后算错一个数字。普通 DPO 只会把 $y^+$ 当成“赢家”全力拉高。
TUR-DPO 会进一步检查 $y^+$ 的推理图,如果发现结论节点缺乏支撑、存在 dangling node,或者在重采样时拓扑结构极不稳定,那么这个“赢家”的优势会被削弱,对应样本的训练权重也会下降。换句话说,它不再盲信偏好标签,而是用结构一致性与不确定性做二次校验。
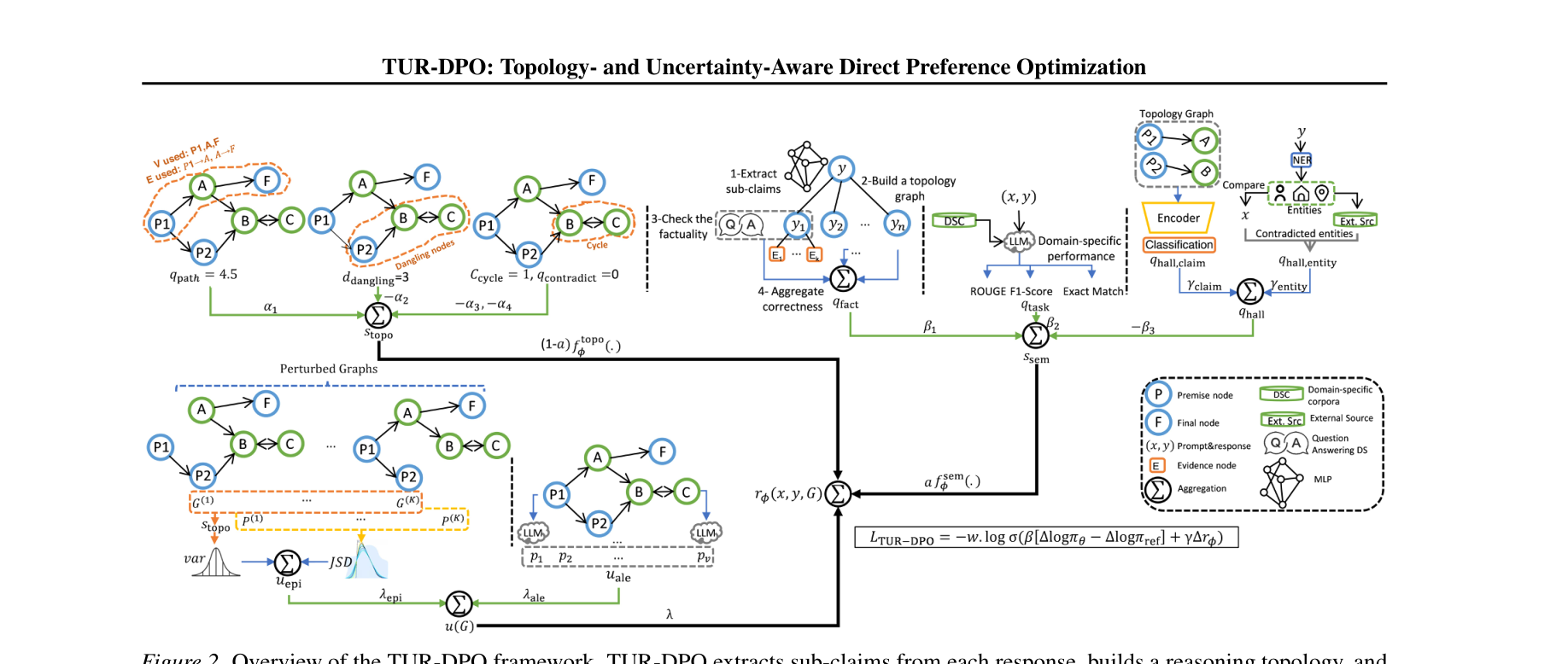 图注:TUR-DPO 从响应中抽取推理图,计算语义分、拓扑分与不确定性,再把 shaped reward 注入 DPO 的优化目标。
图注:TUR-DPO 从响应中抽取推理图,计算语义分、拓扑分与不确定性,再把 shaped reward 注入 DPO 的优化目标。
方法论与技术实现
论文先为回答构建图 $G=(V,E)$,再用拓扑评分衡量推理结构:
$s_{topo}(G)=\alpha_1 q_{path}-\alpha_2 c_{cycle}-\alpha_3 d_{dangling}-\alpha_4 q_{contradict}$
之后将语义分与拓扑分组合成 shaped reward:
$r_\phi(x,y,G)=a f^{sem}_\phi(s_{sem})+(1-a)f^{topo}_\phi(s_{topo})-\lambda u(G)$
其中 $u(G)$ 是不确定性。实例权重则按
$w=clip\left(\frac{\tau_w}{1+\bar u}, w_{min}, 1\right)$
计算。最终训练目标是:
$\mathcal{L}_{TUR-DPO}=-w\log\sigma\left(\beta[\Delta\log\pi_\theta-\Delta\log\pi_{ref}]+\gamma\Delta r_\phi\right)$
实验设置与结论分析
论文在 GSM8K、MATH、BBH、开放问答、摘要等任务上测试基于 Llama 的模型。结果显示 TUR-DPO 相比 vanilla DPO、IPO、KTO、ORPO、SimPO 等方法都有稳定提升,尤其在需要长链推理和结构正确性的任务上收益更明显。
对工程来说更重要的是,它在不引入 PPO 复杂训练环的前提下就改善了校准和鲁棒性,说明“结构奖励 + 不确定性降权”这条路非常值得继续挖。
关键技术亮点分析
- 它把后训练从“标量偏好打分”推进到了“结构化过程质量建模”。
- 不确定性权重给了偏好学习一种柔性的噪声控制方式。
- 很适合推理型、事实型任务,不只是 chat preference。