Learning to Retrieve from Agent Trajectories
从Agent轨迹中学习检索:为Agentic Search量身打造的Retriever训练新范式
作者: Yuqi Zhou, Sunhao Dai, Changle Qu, Liang Pang, Jun Xu, Ji-Rong Wen
机构: 中国人民大学高瓴人工智能学院,中科院计算所AI安全重点实验室
📄 查看 ArXiv 原文
1. 研究背景与痛点
传统的信息检索(IR)系统,无论是早期的稀疏检索(BM25)还是现代的 Dense Embedding 模型,其训练范式和监督信号(如点击、停留时间等)都是围绕人类用户(Human-centric) 设计的。然而,随着像 DeepResearch 等长逻辑链 Search Agent 的崛起,现代搜索引擎的“主要消费者”正迅速从人类转变为自主运行的 Agent。
在 Agentic Search 范式中,原有的假设被彻底打破:
意图的转移: Agent 抛出的 Query 往往不是为了直接获取最终答案,而是为了填补多步推理(Multi-turn Reasoning)中的中间逻辑缺口(information gap)。交互的异构: Agent 并不像人类那样扫视标题然后点击,它们通过观察 Snippet 决定是否下钻浏览(Browse),并在浏览后进行大量的显式推理(Reasoning Trace)。核心痛点: 当前最先进的 Agent 仍在使用面向人类优化的“现成 Retriever”。这种 Retriever 无法理解 Agent 演变的上下文需求,成为制约模型获取高价值信息的最大瓶颈。
2. 核心贡献
为了解决上述 Mismatch,本文突破性地提出了Learning to Retrieve from Agent Trajectories (LRAT) 的新范式。核心贡献如下:
深层 Agent 行为学分析: 系统拆解了 Agent 与检索系统互动的轨迹,论证了 [Browse] 动作是成功的必要条件,并证明了 Agent 浏览行为不带有严重的位置偏见(Position Bias) 。构建完全自监督的对齐框架 LRAT: 无需人工标注,直接从模型自身运行留下的 Trajectory 中提取 Query-Document 对齐监督信号,引入大模型过滤噪声,并创新性地提出“基于推理长度的强度感知优化” 。验证“数据飞轮”的闭环能力: 实验表明,即使 Agent 最终任务失败(Incorrect Trajectories),其搜索中间状态留下的判定反馈依然能有效反哺 Retriever,为真实场景的自驱动进化(Data Flywheel)铺平了道路。
3. 具体案例剖析 (Case Study)
理解 LRAT 的前提是理解深层研究 Agent 的执行轨迹(Execution Trajectory)。一个典型的 Agent 轨迹呈现出不断交替的 [Think] 与 [Action] 循环。例如:
User Query: Which station merged with Immaculate Heart Radio in 2017?
[Think]: 目前还没有关于合并的信息。我们需要搜索关于 2017 年合并的具体细节。
[Search]: Search["Immaculate Heart" "merged" "2017"]
[Information]: (Retriever返回前10名候选文档及Snippet)
[Think]: Doc [2295] 的摘要里提到了 Relevant Radio,里面可能包含具体的合并日期,我们仔细阅读一下这篇文档内容。
[Browse]: Browse[DocID: 2295]
[Information]: (返回完整全文,确认了合并方)
[Think]: (经过几百 Token 的推理计算) 我已经找到答案了,电台是 WMJR...
[Answer]: The station is WMJR (Nicholasville, KY).
在这个案例中,Agent 放过了 Doc [3948] 而主动选择 [Browse] 候选列表中的 Doc [2295],并在浏览后生成了大量的高质量 [Think] 思考。这构成了极佳的天然隐式反馈,指示着在特定 Query 上下文下,文档真实的“功能性效用”。
4. 方法论与技术实现
如图所示,LRAT 的技术管线主要包含两大部分:监督信号挖掘与相关性强度感知的网络训练。
4.1 挖掘逐步精炼的监督信号
朴素正负样本构建 (Naive Relevance Mining): 提取 [Search] → [Browse] 的转移对。在同一个召回 List 中,被浏览的 $d_{t+1}$ 视为正样本,其余所有未被浏览的候选自动构建为无偏负样本池 $\mathcal{N}_t = \mathcal{D}_t \setminus \{d_{t+1}\}$。推理感知的正样本过滤 (Reasoning-Aware Positive Filtering): Agent 仅凭 Snippet 选中的内容有时名不符实(点开后发现没用)。通过引入 LLM-as-a-Judge,评估 Agent 浏览完毕后紧跟的 [Think] 轨迹,判断 Agent 是否真的“吸收并利用”了该文档推进任务。如果不匹配,则直接丢弃该伪正例。
4.2 强度感知训练 (Intensity-Aware Training)
这是全篇最精彩的机制迁移之一: 经典 IR 中有一个公认的结论——用户在一个网页停留的时间(Dwell Time)越长,该网页越相关。在 LLM 身上,这一表现被映射为了“推理计算消耗”(Post-browse Reasoning Length) 。Agent 浏览高价值线索后,往往会生成很长的 Thought 链来进行深层逻辑推演。
受时间感知点击模型的指数饱和效应启发,作者使用 Agent 在浏览动作后的生成的 Token 数量 $l$ 计算平滑相关性权重 $w$:
$$ w = \frac{1}{\mu_{\text{raw}}} \left( 1 - \exp\left(-\frac{\ln 2 \cdot l}{\beta}\right) \right) $$
其中,$\beta$ 是所有轨迹中推理长度的中位数作为半衰参数,使得边际效用随着 Token 增多而逐渐饱和,防止极端异常长的输出带崩梯度。
最终,将该权重纳入经典的 InfoNCE 损失函数中,指导基于 Bi-encoder 的 Dense Retriever 微调(带权重强度的对比学习):
$$ \mathcal{L} = - \frac{1}{N} \sum_{i=1}^{N} w_i \cdot \log \frac{\exp(s(q_i, d_i^+)/\tau)}{\exp(s(q_i, d_i^+)/\tau) + \sum_{d^- \in \mathcal{N}_i} \exp(s(q_i, d^-)/\tau)} $$
5. 实验设置与结论分析
实验基准与基座设置: 使用面向 Agent 的复杂深层搜索评测集 InfoSeek-Eval(In-Domain)和 BrowseComp-Plus(OOD)。Retriever 选用 Multilingual-E5-Large 和 Qwen3-Embedding-0.6B;搭配的 Agent 涵盖了小参数专项模型(如 AgentCPM 4B)至通用千亿参数模型(如 GPT-OSS-120B, GLM-4.7-358B)。
端到端性能大幅提升: 在 InfoSeek-Eval 上的 Success Rate 最大相对增幅达到了 38.2%,且在使用更少执行步骤(Avg. Steps 下降达 30%)的前提下达成了更高胜率,体现了命中精度质的飞跃。OOD泛化能力突出: 在完全不包含训练分布的 BrowseComp-Plus 集合上,证据召回率 (Evidence Recall) 和最终回答成功率均获得稳定的正向收益,证明 Retriever 真的学会了适配多轮 Agentic 意图,而不仅仅是过拟合题库。Ablation Study(消融验证): 实验证实了“从所有未浏览文档中抽样负例 (Naive)”是有效的;进一步叠加“利用后续推导长度重加权 (Reweight)”策略是全套框架里贡献核心涨点的一把钥匙。数据飞轮模拟 (Data Flywheel): 引入即便是因为超时或推理错误导致任务失败的“Incorrect Trajectory”,由于中间包含对个别文档的真实价值评价,同样能带来收益 (+18.9%),这意味着这套系统在真实流式部署中能够产生“左脚踩右脚”的闭环增强效应。
6. 关键技术亮点与从业者启发
破解传统 LTR 的 Position Bias 魔咒: 人类搜索由于视觉注意力的限制,排在后面的文档不被点击常常是因为“没看到”。但 Agent 处理多候选时,对于文本流上下文是无差别扫描的,这让同一召回列表中未被 Browse 的文档成了天然无偏置、不需做 Debiasing 处理的高质量 Hard Negatives。这大大简化了对齐训练中的负样本构建工程。Dwell Time 向 Thinking Token 的精妙映射: 把搜索点击系统里经典的人类行为隐式反馈特征,完美映射到了当前火热的 "LLM Test-time Scaling" (如 o1 类型的长思考) 的内在表征中。长考即高相关,这套直觉设计为未来开发多模态、跨端 Agent 偏好对齐提供了一个非常具有想象力的新视角。让 Retriever 融入 Agent 的心智: 目前大部分 RAG 系统将检索和生成做极度解耦。这篇论文深刻指出,Agentic Search 中动态、碎片的子查询与人类的一步直达式 Query 语义差异巨大。将 Retriever 用 Agent 自己的工作流轨迹“回炉重造”,这是未来两年解决 RAG 系统幻觉与信息获取天花板的最核心技术路径之一。
突破大语言模型智能体能力边界:策略引导的探索
Expanding LLM Agent Boundaries with Strategy-Guided Exploration
作者机构: Andrew Szot, Michael Kirchhof, Omar Attia, Alexander Toshev (Apple)
论文链接: 📄 查看 ArXiv 原文
🔍 研究背景与痛点 (Background & Pain Points)
在后训练阶段(Post-training)引入强化学习(RL)是当前提升 LLM Agent 复杂任务能力(如计算机控制、工具调用、代码生成)的核心驱动力。然而,在 Agentic 场景下,探索(Exploration) 面临着极为严峻的挑战:
极度稀疏的奖励信号: 智能体通常只有在完成整个长序列任务后才能获得二元(成功/失败)奖励。语言-动作空间的复杂性: 与雅达利游戏或机器人连续控制不同,LLM 的输出空间是无穷的自然语言/代码/API调用。基于预训练和 SFT 初始化的 LLM 会在某些高概率输出上形成严重的“策略坍塌(Policy Collapse)”。传统 RL 的天花板: 大量实证表明,针对 LLM 的标准强化学习(如 PPO、GRPO)倾向于仅仅微调和提纯 Base Model 已经掌握的行为 ,而极难“无中生有”地探索出解决全新困难任务的轨迹。表现为:RL 训练后的极限 pass@1 很难突破 Base Model 采样几千次所能达到的极限 pass@k。
为了解决上述问题,当前领域内尝试了如熵正则化(Entropy Regularization)、基于随机网络蒸馏的内在奖励(RND)等方法,但在重度依赖逻辑推理的 Agentic 环境中效果有限(增加输出 Token 的熵往往只会带来语法错误或坐标偏移,而非语义上的有效探索)。
💡 核心贡献 (Core Contributions)
Apple 研究团队提出了一种极具工程实用价值且无需额外模型的探索方法——策略引导的探索(Strategy-Guided Exploration, SGE) 。其核心逻辑是:将探索的空间从底层的“动作空间”转移到高层的“自然语言策略空间” 。主要贡献包括:
策略提示(Strategy Prompting): 强制 LLM 在输出具体的执行动作前,先生成一段精炼的自然语言策略(Strategy),描述如何向目标推进。混合温度采样(Mixed-Temperature Sampling): 针对 Rollout 数据收集阶段,采用不对称的温度设定:用高温度(如 $T=1.2$)采样策略 Token 以最大化高维探索,用低温度(如 $T=0.7$)采样动作 Token 以保证代码/UI操作的精确执行。策略反思(Strategy Reflection): 在 Rollout 阶段引入 In-context 历史反馈,将之前失败(或成功)的策略喂给当前 Prompt,要求模型进行自我批判并生成截然不同的新策略,打破同质化采样的死循环。突破 Base Model 极限: 在 UI 交互、工具调用、多步编程和具身智能四个跨度极大的领域全面超越了 GRPO、EntropyAdv、RND 等 Baseline,最关键的是,SGE 成功突破了基座模型的 pass@k 上限 ,证明其真正学到了 Base Model 无法通过简单随机采样解决的新任务。
🛠 具体案例剖析 (Case Study)
为了直观感受 SGE 与标准 RL 采样的差异,我们来看两个论文中的具体 Case:
Case 1: AndroidWorld 环境中的 UI 交互探索
任务: 在 Markor APP 中创建一个名为 calm_umbrella_backup.txt 的新笔记。当前屏幕状态已经输入了文件名,但扩展名默认是 .md,需要改成 .txt。标准采样(GRPO): 面对屏幕截图,由于缺少高层指导,模型倾向于在输入框的文字坐标附近盲目尝试点击,甚至尝试通过打字来修改扩展名,但 UI 逻辑要求必须点击“扩展名下拉菜单”。SGE 采样: 借助混合温度采样,SGE 在高层策略空间展开探索,生成了诸如:“I need to indicate that the file should be named... with the .md extension, so I select the name field...” 这样的策略。在多次 Rollout 中,某一次高温度生成的策略成功意识到了需要点击下拉菜单,随后低温度的动作生成精确预测了该 UI 元素的 $(x,y)$ 坐标,从而获得正向 Reward 供 RL 更新。
Case 2: 编程环境中的“负面策略反思(Negative Reflection)”
任务: LeetCode Hard 级别的两人相遇点计算。失败的历史策略: 智能体之前生成的策略错误地假设了“相遇建筑必须严格在两人初始位置的右侧且高于两者”。SGE 注入的 Reflection Prompt: Here is my previous FAILED strategy: ... First, critique the failed strategy and how it can be fixed. Be precise...SGE 新生成的修正策略: 智能体在 Prompt 引导下输出:“The previous failed approach incorrectly assumes that... While this condition is necessary, it is not sufficient... Critical Insight: The movement rule says that...” 。通过直接把过去的坑作为 Context 传入,模型被强迫探索出了新的算法路径,避免了在同一个死胡同里浪费大量的 RL 采样算力。
⚙️ 方法论与技术实现 (Methodology & Implementation)
SGE 的实现非常优雅,它完全不改动基础强化学习算法(如 GRPO)的损失函数和梯度更新机制,仅仅在数据收集(Rollout)阶段的采样机制 上做文章。
1. 策略提示与概率分布重构
将标准的思维链采样 $y_1 \sim \pi(\cdot \mid g, o_1)$ 改造成先进行策略采样。整个输出的分布变为:
$$ \pi(a_t|y_t, s_t, o_t) \pi(y_t|s_t, o_t) S_\pi(s_t|o_t) $$
其中 $S_\pi$ 代表特定的策略采样分布,它由特制的 Prompt 和独立配置的温度参数构成。
2. 混合温度采样 (Mixed-Temperature Sampling)
在推理生成阶段,对同一个输出流实施两段式温度控制:
策略 Token ($s_t$): 使用较高温度 $\tau_s$(实验中设置为 1.0 ~ 1.2)。这使得 $S_\pi$ 能覆盖广泛的高层意图。剩余 Token ($y_t, a_t$): 使用正常/较低温度 $\tau$(实验中设置为 0.6 ~ 0.7)。因为在给定了高层策略后,动作的执行必须尽可能遵守语法或 UI 规范,如果动作也使用高温度,会导致诸如代码缩进错误、UI点击偏差等无意义的探索。
3. 策略反思 (Strategy Reflection)
为防止在一次 PPO/GRPO 迭代中并行生成的 $K$ 条轨迹同质化,SGE 维护了一个策略回放缓冲区。
在训练循环的 Rollout 阶段,维护两个集合:成功策略缓存 $\mathcal{B}_G$ 和失败策略缓存 $\mathcal{B}_B$。
以概率 $p_B$(如 0.25)触发负面反思:从 $\mathcal{B}_B$ 随机采样一条同任务下曾经失败的策略(如果环境支持,还会附带 Error Log 比如测试失败输出),拼接到 Prompt 中,迫使模型反思并输出新策略。
📊 实验设置与结论分析 (Experiments & Analysis)
实验环境: 涵盖 4 个不同维度的 Agent 任务,分别是 AndroidWorld(多步视觉UI控制)、Language Rearrangement(三维具身智能物体重排)、Coding(LeetCode Hard 多步代码修改)、AppWorld(多步API调用)。基座模型: Qwen2.5-VL-3B (Android), Qwen3-4B-Instruct (LangR, Coding), Qwen3-8B (AppWorld)。Baseline: 标准的 GRPO,以及强化探索的 Entropy Advantage、RND(随机网络蒸馏)、RLAD(抽象发现强化学习)。
核心结论:
显著提升最终 RL 性能: SGE 在四个环境中的平均相对成功率比表现最好的 Baseline 高出 27%。成功突破 Base Model 极限 (Max Pass@k): 论文中极其重要的一项发现是:在多轮 Coding 任务中,Base Model 的 Pass@2048 极限停留在 69%(意味着无论怎么采样都无法解决剩下的 31% 问题)。最好的 Baseline (GRPO) 最终训练收敛的 Pass@1 仅为 64%,无法获得新能力。而 SGE 训练后的单次执行成功率达到了 73%,实打实地跨越了基座的认知边界,解锁了新技能。 优异的泛化性 (Generalization): 在 Zero-Shot 评测未见过的测试集任务时(Table 1),SGE 同样全面领先。例如在 AndroidWorld 中,SGE 的泛化成功率为 36.7%,而 GRPO 仅为 21.9%。消融实验与缩放定律: 移除混合温度采样会导致性能骤降,表明单纯的全局高温度采样对 Agent 而言是灾难。此外,实验表明 SGE 的发挥极度依赖基座模型本身的推理底座:在 600M 模型上 SGE 几乎无效,在 4B 和 8B 模型上增益极为显著。
🌟 关键技术亮点分析 (Technical Highlights)
解耦“语义探索”与“动作执行”: 这是本文最核心的 Engineering Insight。对于 LLM,直接拉高输出温度进行 PPO 探索,在数学证明题可能 work,但在 Agent 场景(如写一段严谨的 JSON Tool Call 或 Python 语法)注定产生大量语法层面的废料。SGE 巧妙地用“不对称温度控制”将两层解耦,高层天马行空,底层精确执行。时间维度的探索扩展 (Temporally Extended Exploration): 传统的单步 RL 探索往往只是在状态动作空间里布朗运动。SGE 生成的一段文字 Strategy,实质上等价于传统分层强化学习(HRL)中的“Option”或长期目标,这为稀疏奖励下的长序列寻路提供了强有力的引导。无缝集成现代 LLM RL 栈: SGE 完全没有动 GRPO 的底层优势函数(Advantage)计算逻辑和 KL 散度约束,这意味着它可以像一个插件一样无缝结合到现有的 DeepSeek-Math / OpenRLHF 等训练框架中,只需修改 Rollout 服务器端的 Prompt 生成逻辑和采样 API 即可,工程落地成本极低。
大语言模型的 Agent 技能:架构、获取、安全及未来发展方向
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
作者: Renjun Xu, Yang Yan
机构: 浙江大学 (Zhejiang University, China)
📄 查看 ArXiv 原文
💡 研究背景与痛点
随着大语言模型 (LLMs) 能力的飞速扩展,它们作为自主智能体 (Autonomous Agents) 在实际应用中面临着一个根本性矛盾:通用模型具备广泛的世界知识,但极度缺乏解决现实世界复杂任务所需的专业领域程序性知识 (Procedural Knowledge) 。
过去解决这一问题的主流方案存在明显局限:
微调 (Fine-tuning): 成本高昂,且难以实现能力的动态组合 (Composability)。RAG (检索增强生成): 外部知识是被动的,无法为 Agent 提供多步工作流指导、打包可执行代码,或在运行时动态修改 Agent 的工具权限。工具调用 (Tool Use / Function Calling): 传统的工具调用是原子化的(执行并返回结果),它们无法重塑 Agent 对任务的理解方式。
在此背景下,Agent Skills (技能工程) 作为一种全新的范式应运而生:从依赖模型权重或临时 Prompt,转向一种模块化、基于文件系统的抽象层。技能不再是单一的模型或 Prompt 模板,而是一个包含结构化指令、脚本、参考文档的独立上下文包 ,Agent 可以按需动态加载,从而实现免重新训练的能力扩展。
🚀 核心贡献
本文是首篇全面系统性论述“Agent Skills”范式的综述文章,填补了现有 LLM Agent 或 Tool Use 综述在“技能抽象层 (Skill Abstraction Layer)”上的空白。其核心贡献包括:
架构基础解析: 系统剖析了基于 SKILL.md 规范的渐进式加载 (Progressive Disclosure) 架构,并厘清了 Agent Skills 与 MCP (Model Context Protocol) 之间互为补充的 Agentic Stack 关系。技能获取分类学: 构建了涵盖人工编写、基于强化学习的技能库 (SAGE)、自主探索发现 (SEAgent)、组合合成等多种维度的技能获取 (Skill Acquisition) 方法分类。CUA 部署生态评估: 定量分析了计算机使用智能体 (Computer-Use Agent, CUA) 作为技能部署核心领域的基准测试现状与架构演进。首个安全与治理框架: 综合了多项实证研究(揭示社区技能中存在 26.1% 的高危漏洞率),原创性地提出了技能信任与生命周期治理框架 (Skill Trust and Lifecycle Governance Framework) ,包含四级验证门槛与动态权限分级。前沿挑战指引: 提出了跨平台可移植性、在大规模技能库中路由、基于能力的权限模型等 7 大开放性研究挑战。
🔍 具体案例剖析 (Case Study)
为了直观理解 Agent Skills 与传统 Tool Use 的本质区别,论文给出了一个“PDF 处理 (PDF-processing)” 的典型案例。
【输入/场景】 用户给出指令:“帮我填写这份 PDF 表单。”
【传统 Tool Use 方案】 read_pdf() 的函数,获取 PDF 文本,然后尝试生成回复。它本质上只是调用了一个 API,Agent 自身并不知道处理复杂 PDF 表单的最佳工程实践是什么。
【Agent Skills 方案】 pdf-processing 技能时,系统会执行基于渐进式披露 (Progressive Disclosure) 的三级动作:
Level 1 (Metadata) 匹配: 系统的 System Prompt 中预加载了轻量级的 YAML 元数据 (仅几十个 Tokens),Skill Router 发现意图匹配。Level 2 (Instructions) 注入: 触发后,Agent 会将该技能的 SKILL.md 核心内容作为隐藏的元消息 (Meta-message) 注入上下文。这不只是一个工具,而是一套“员工入职指南” ——告诉 Agent 应该分几步走、如何处理解析异常、推荐使用哪些内置的 Bash 命令。Level 3 (Resources) 动态加载: 如果 Level 2 的指导认为有必要,Agent 会进一步按需加载该技能包下的 scripts/extract.py 等可执行脚本或参考文档。
【结果】 技能通过注入程序性知识和修改执行上下文,改变了 Agent 的“准备状态 (Preparation)” ,随后 Agent 才开始利用这套丰富的领域认知去规划并完成任务,大幅降低了试错率和 Token 消耗。
⚙️ 方法论与技术实现
本文从架构、获取和部署三个维度,对 Agent Skills 的技术体系进行了深度解构:
1. 架构基石:Skills 与 MCP 的融合 (The Agentic Stack)
Agent 的现代化堆栈正在由两大互补层构成:
Agent Skills (提供 "What to do"): 以 SKILL.md 为核心的目录结构,负责提供程序性知识。它基于文件系统,由 Agent 在触发时加载,直接修改上下文与操作权限。Model Context Protocol, MCP (提供 "How to connect"): 标准化的 JSON-RPC 2.0 协议,负责提供外部系统的数据和工具连接性。
2. 技能的获取范式 (Acquisition Modalities)
除了人类直接编写 (Human-authored) 以外,学术界正探索如何让 Agent 自主学习技能:
RL 结合技能库 (例如 SAGE): 通过顺序展开 (Sequential Rollout) 机制,Agent 在相似任务链中持续保留生成的技能。结合 GRPO 强化学习框架,不仅奖励任务结果,还包含一个专门的 Skill-integrated Reward 信号来奖励高质量、可复用的技能创建。自主探索发现 (例如 SEAgent): 引入世界状态模型 (World State Model) 进行评估,并通过课程生成器 (Curriculum Generator) 从软件操作指南中不断生成进阶任务,从专才向通才进化。多智能体编译 (Skill Compilation): 将复杂的多智能体系统“编译”为单智能体技能库,能大幅降低 Token 消耗并保持低延迟。
3. 主要部署环境:CUA (计算机使用智能体) 堆栈
由于操作 GUI 界面本质上需要感知、推理与动作的复合序列,CUA 成了技能范式最天然的试验场。诸如 UI-TARS 2 等架构通过视觉与动作统一建模,结合数据飞轮与多轮 RL 训练,正在持续推高 CUA 的基准性能(详见实验部分)。
📊 实验设置与结论分析
虽然本文是综述,但汇总了该领域最新的 Benchmark 数据与安全性实证结论:
性能与基准测试 (CUA Benchmarks)
在 OSWorld 测试中,早期模型的成功率仅为个位数。但结合了高阶视觉 Grounding 和强化学习的架构(如 Proprietary 系统和 CoAct-1)已经达到了 72.6% ,与人类基线 (72.4%) 相当。
RL+技能库提升: SAGE 框架在 AppWorld 测试中,相较于纯 GRPO 基线,绝对成功率提升了 8.9% ,同时由于技能的复用性,推理步数减少 26%,Token 消耗锐减 59% (这对生产环境的成本控制至关重要)。
安全侧实证发现 (极度严峻)
漏洞泛滥: 基于对超 4 万个社区技能的扫描发现,26.1% 的技能至少包含一个漏洞 (数据泄露占13.3%,提权占11.8%)。包含可执行脚本的技能风险是纯指令技能的 2.12倍 。技能层面的提示词注入 (Prompt Injection): 攻击者可以将恶意指令嵌入极长且被 Agent 深度信任的 SKILL.md 文件中,从而绕过系统的常规安全护栏(例如滥用 "Don't ask again" 授权来窃取本地凭证)。
🌟 关键技术亮点分析与洞察
从“大模型”走向“插件化脑区”: 渐进式披露 (Progressive Disclosure) 架构是一项优雅的工程创新。它解决了大模型“上下文窗口容量”与“无限领域知识注入”之间的矛盾。通过仅预加载轻量化 Metadata(约30 tokens),实现了零惩罚的海量技能库路由。原创的生命周期安全治理框架 (Trust & Lifecycle Governance): 本文并未停留在提出安全问题,而是首创性地提出了一个映射系统:将静态分析、语义匹配、沙箱运行、Manifest 校验四大关卡 (G1-G4),与非信任/社区/组织/官方四级信任等级 (T1-T4) 对齐,并赋予递进式的工具/网络权限。这为未来大厂构建 Agent App Store 提供了理论基础。技能扩张的“相变”现象 (Phase Transition): 文章揭示了一个极其重要的限制——当技能库的规模增长到某个临界点时,Agent 的技能路由/选择准确率会发生断崖式下跌 (Phase Transition) 。这表明,虽然技能解决了“如何做”的问题,但在企业级部署中,成百上千个技能引发的“组合爆炸与动态路由”将是未来 1-2 年内最重要的算法攻坚点。
面向LLM智能体的强化世界模型学习
作者: Xiao Yu, Baolin Peng, Ruize Xu, Yelong Shen, Pengcheng He, Suman Nath, Nikhil Singh, Jiangfeng Gao, Zhou Yu
机构: 哥伦比亚大学 (Columbia University), 微软研究院 (Microsoft Research), 达特茅斯学院 (Dartmouth College)
📄 查看 ArXiv 原文
1. 研究背景与痛点
大语言模型(LLMs)在以语言为中心的任务上取得了巨大成功,但当将其作为自主智能体(Autonomous Agents)放置于复杂的长视野(Long-horizon)环境中时,往往表现挣扎。这种挣扎的核心在于:模型缺乏预判动作后果并适应环境动态的能力,即缺乏“世界模型(World Model)”能力。
传统的后训练范式在此场景下存在显著痛点:
预训练目标的错位: 标准的 Next-token prediction 侧重于静态文本语料的语言理解与生成,而 Agent 智能体需要关于因果、状态流转的动态推理能力。基于监督微调(SFT)的局限: 现有的世界模型注入方法多依赖专家级轨迹或强模型(如GPT-4)合成高质量数据进行 SFT。SFT 强迫模型追求 Token 级别的绝对保真(Exact wording),忽略了语义等价性,极易导致“模型崩溃(Model Collapse)”,且严重依赖昂贵的数据标注。稀疏奖励下的策略强化学习(Policy RL)瓶颈: 在复杂环境中,定义准确的 Task-success 奖励极其困难且极其稀疏,导致直接跑策略 RL 难以收敛且可扩展性差。
2. 核心贡献
本文提出了一种全新的、完全自监督 的训练范式:强化世界模型学习(RWML, Reinforcement World Model Learning) 。通过让 LLM 学习环境的状态转移函数(Transition Function),在正式的策略优化(Policy RL)之前,将其打造为一个动作条件下的世界模型。
基于 Sim-to-Real Gap 的强化学习: 彻底放弃了 SFT 路线。模型被要求生成动作执行后的“模拟下一状态”,并将其与环境中实际观测到的真实状态在预训练 Embedding 空间中计算余弦相似度。这种余弦相似度作为 Reward 驱动 GRPO(Group Relative Policy Optimization)训练,鼓励模型捕捉核心语义流转而非生硬地模仿文本。无需专家数据与稀疏奖励: 整个 RWML 阶段无需任何 Task-success 信号,也无需强模型标注。仅依赖模型自身在环境中的探索轨迹(Rollouts)即可构建训练集,极具扩展性(Scalable)。重塑 Mid-training 范式: 实验证明,经过 RWML “预热”过的模型,不仅自身规划能力大幅增强,在后续叠加 Policy RL 后,性能超越了直接跑 Policy RL 以及那些使用了专家示范的 SFT 基线,同时极大缓解了灾难性遗忘(Catastrophic Forgetting)。
3. 具体案例剖析 (Case Study)
论文在两个典型长链路智能体环境中展示了 RWML 为模型带来的决策质变(见图5):
ALFWorld(具身环境,目标:将一把刀放到边桌上):
Base Model: 毫无常识规划,先跑去打开“抽屉1”发现没东西,又去检查“柜子3”,陷入盲目试错,最终30步耗尽失败。
RWML Model: 在生成动作前,通过内部 <think> 标签构建对世界的预判:“刀最合理的位置通常是台面(countertop),我先去 countertop 1 看看”。随后直接到达目标地获取了刀,仅用5步(success in 5 steps)干净利落地完成任务。
$\tau^2$ Bench(高难度多轮客服/工具使用场景,目标:排查用户手机无服务问题):
Base Model: 只知道顺着流程往下走,向用户机械地索要手机号和客户ID,没有真正“诊断”状态。
RWML Model: 敏锐捕捉到了之前多轮对话中潜藏的系统状态变更。模型在其推理过程中指出:“等等,用户之前尝试过重启,并且我查状态栏发现飞行模式是开启的 ...这可能就是没信号的原因”。基于这个“因果洞察”,模型直接向用户提问关于飞行模式的问题,迅速破局。
4. 方法论与技术实现
RWML 的核心是将“下一个状态预测”转化为强化学习环境中的生成任务,整体流程包含以下几个关键步骤:
Step 1: 交互数据收集 (Rollout Generation)
Step 2: 难样本挖掘 (Subsampling "Easy" Samples)
Step 3: 构建二值化 Embedding 奖励函数
Step 4: 基于 GRPO 的强化优化
5. 实验设置与结论分析
实验环境设置: 采用 Qwen2.5-7B (ALFWorld) 与能力更强的 Qwen3-8B ($\tau^2$ Bench) 作为基座模型。所有训练采用 8×B200 算力集群。
1. RWML 自监督带来的巨大增益:
2. 结合 Policy RL 的终极超越:
3. 相比 SFT,RL 显著缓解灾难性遗忘: 参数权重更改(Weight Change Analysis) 表明,WM SFT 对模型大量深层参数进行了激进的重置,而 RWML 仅在特定层级进行了小范围的点式参数调整(Point-wise Updates),表现得极为“克制”和高效。
6. 关键技术亮点分析 (Practitioner's Takeaways)
这是一篇对 LLM Agent 领域具有启发性的方法论文章。对于业界从业者而言,本文释放了三个强烈信号:
SFT 并非构建 World Model 的良方: 由于自回归 SFT 天生追求 Token 级别的强制对齐,面对具有随机性或强语义等价性的系统状态反馈时(比如同样表达“门没开”和“门被锁了”),SFT 惩罚过重,反而会毁掉大模型自身已有的内在表征。改用 Embedding Reward 驱动的强化学习是极大的一条“解题捷径”。Mid-training 的自动化工程极具价值: 获取 Task-success Reward 的代价往往极高(例如要求大模型自动执行数百个步骤后才得知是否成功部署了微服务),而获取中间态的 Next-state 是低成本甚至无成本的。利用海量无标注环境日志去跑 RWML,能作为 Agent Domain-adaptive Pretraining 后极佳的接力器。LLM-as-a-judge 存在隐患: 消融实验暴露出,使用 Qwen3-235B 作为裁判进行奖励打分,不仅训练性能跌底(ALFWorld 上暴跌至 3.6%),还极其容易被目标模型生成的废话长文或特定句式(Reward Hacking)蒙骗。反而是死磕“向量空间语义距离”这条硬核指标更加稳健。
SmartSearch: Process Reward-Guided Query Refinement for Search Agents
SmartSearch:过程奖励引导的搜索智能体查询优化框架
作者: Tongyu Wen, Guanting Dong, Zhicheng Dou
机构: 中国人民大学 (Renmin University of China)
📄 查看 ArXiv 原文
🔍 研究背景与核心痛点
近年来,基于大语言模型(LLM)的搜索智能体(Search Agents) 在解决知识密集型任务上展现了巨大潜力。它们能够通过迭代式地调用外部搜索引擎,以多轮 Thought-Action-Observation 的范式(如 ReAct)来应对静态 RAG(检索增强生成)难以处理的复杂深度探索任务。
然而,现有的基于提示工程(Prompting)或微调(SFT/RL)的方法往往将重点放在优化智能体的推理范式(Reasoning Paradigms) 或最终结果的正确性上,却严重忽略了中间搜索查询(Intermediate Search Queries)的质量 。
核心痛点:
在多轮搜索轨迹中,低质量的中间 Query(例如缺失关键实体修饰、意图冗余)会导致检索返回不相关甚至误导性的信息(Unexpected Results),进而使整个推理轨迹偏离正确方向(Derailment)。现有的结果导向奖励(Outcome Reward)机制过于稀疏,无法为中间查询步骤提供细粒度的信用分配和纠偏指导。
💡 核心贡献
视角创新: 首次将优化重点聚焦于搜索智能体推理过程中的“中间查询质量”,并利用细粒度过程奖励(Process Reward)直接驱动查询能力的提升。提出 SmartSearch 框架: 引入两大核心机制:双层信用评估(Dual-Level Credit Assessment) 用于提供过程奖励;过程奖励引导的查询修正(Query Refinement) 用于自动识别并重写低质量 Query,从而生成更优的对比轨迹。三阶段面向查询的课程学习框架: 设计了一套由浅入深的训练 Pipeline,依次为:基于查询质量筛选的 SFT(模仿学习)、查询生成对齐(DPO)、以及查询感知的策略优化(Agentic RL / GRPO),逐步将高质量查询能力内化到模型权重中。卓越的实验结果: 在 4 个知识密集型问答基准(如 2WikiMQA、HotpotQA 等)和 2 个开放 Web 探索基准(GAIA、WebWalker)上,一致超越了现有的基于 Prompt 和 RL 的先进 Search Agent 基线模型(如 Search-o1, Search-R1, StepSearch等)。
📖 具体案例剖析 (Case Study)
论文中的 Table 5 & 6 生动展示了低质量查询如何误导模型,以及 SmartSearch 的 Query Refinement 机制 如何力挽狂澜:
【用户问题】
"An Annapolis Story" 这部电影主演中,哪位美国舞台、电影和电视演员出生于1914年2月15日?
【正确答案】
Kevin McCarthy
🔴 原始失败轨迹 (Original Model Output):
<think> ...首先找出电影主演,然后查他们的生日... </think>
<search> stars in "An Annapolis Story" </search>
<result> ...主演包括 John Derek, Diana Lynn 和 Kevin McCarthy... </result>
<think> ...接下来查Kevin McCarthy的生日... </think>
<search> birthdate of Kevin McCarthy </search> // ⚠️ 痛点:Query意图模糊(同名歧义)
<result> ...Kevin Owen McCarthy (出生于1965年1月26日) 是一位美国政治家,众议院多数党领袖... </result>
<think> 生日是1965年,不符合1914年的条件,可能指的是另一个演员... </think>
🟡 过程奖励评估 (Process Reward):
Score: 0
Explanation: 搜索意图是必要的,但检索结果未包含演员Kevin McCarthy的出生日期,而是包含了政治家Kevin McCarthy的信息。
🟢 SmartSearch 查询修正与重生成 (Query Refinement & Regeneration):
[Refined Query] <search> birthdate of Actor Kevin McCarthy </search> // 修正后:加入了Actor消歧
[New Result] ...Kevin McCarthy (February 15, 1914 – September 11, 2010) was an American actor...
[New Think] 确认了演员Kevin McCarthy的生日符合题目要求...
[Answer] Kevin McCarthy
这个对比直接为 DPO 训练阶段提供了极高质量的偏好对(Preference Pairs),教会模型在面临歧义时如何生成高质量的 Search Query。
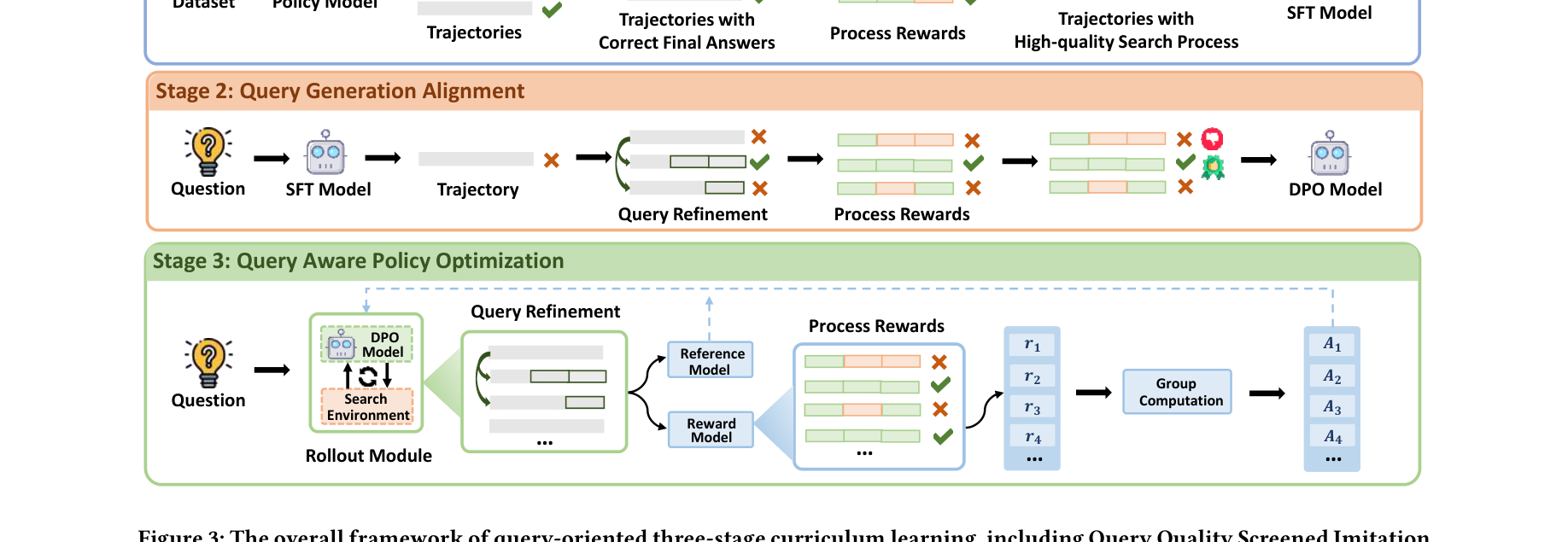
图注:SmartSearch的三阶段课程学习框架:阶段1-基于查询质量过滤的SFT;阶段2-使用Query Refinement构造偏好数据进行DPO对齐;阶段3-结合过程奖励的GRPO策略优化。 ⚙️ 方法论与核心技术实现
SmartSearch 由两大机制与三阶段训练范式构成。
1. 过程奖励:双层信用评估 (Dual-Level Credit Assessment)
为了衡量每个搜索回合 $t$ 的 Query 质量,论文定义了基于三大原则(新颖性、必要性、相关性)的评估机制:
基于规则的新颖性评估 (Novelty Check): 通过计算当前检索文档与历史回合检索文档的重叠度来判断 Query 是否冗余。若重叠文档数 $O^t$ 大于阈值 $K$,则 $S_t^{\text{novel}}=0$(冗余),否则为 $1$。基于模型的有用性评估 (Usefulness Check): 使用轻量级评分模型 $\text{LLM}_{\text{eval}}$ 评估检索结果是否推进了最终答案的解决:
2. 查询修正机制 (Query Refinement)
针对判定为低质量的查询($S_t = 0$),使用轻量级修正模型根据解释文本重写 Query:纠正后的节点 重新开始执行后续的 Rollout 轨迹,形成新的修正轨迹(Revised Trajectory)。该机制极大地提升了轨迹探索的效率。
3. 三阶段课程学习框架 (Three-Stage Curriculum Learning)
阶段 1: Query Quality Screened Imitation Learning (SFT) 所有中间查询必须高质量 (即 $\forall t, S_t=1$)。这避免了模型在早期阶段模仿到低效甚至错误的搜索行为。阶段 2: Query Generation Alignment (DPO) 阶段 3: Query Aware Policy Optimization (GRPO)
📊 实验设置与结论分析
实验配置: 基座模型选用 Qwen2.5-3B-Instruct,评测和修正模型同样使用该轻量级模型(通过强大的Teacher模型如Qwen-32B打标签后蒸馏获得,以兼顾效率与准确率)。环境包括本地 Wiki 检索库以及真实 Web 环境(Serper API)。
核心结果:
知识密集型问答(2WikiMQA, HotpotQA, Bamboogle, Musique): SmartSearch 取得了最强综合表现,平均 EM (37.5%) 和 F1 (47.2%) 相比亚军(如 ReasonRag, StepSearch)均有极为显著的提升(约19%~25%的相对增幅)。开放 Web 探索泛化性(GAIA, WebWalker): 尽管仅在 Wiki-based 本地搜索集上进行了训练,SmartSearch 在未知域 Web 搜索测试中同样达到 SOTA(在 GAIA 上 EM 达 13.4%),证明其习得的“产生高质量 Query”的能力具有普适性。搜索效率分析 (Search Efficiency): 数据表明 SmartSearch 的 API 调用更少且效率更高。因为它极大减少了因为低质量 Query 导致的无效搜索或失败搜索循环。
🌟 资深从业者视角的关键亮点
破解了Agentic RAG的一大盲区: 当前做 Agent 训练很容易陷入“模型通过不断试错穷举来碰对答案”的陷阱(依赖高频Rollout)。本文敏锐地抓住了搜索 Agent 的本质:Query 是与环境交互的唯一 Interface,垃圾进则垃圾出 。通过显式优化中间 Query,大幅缩短了搜索路径(Search Efficiency 提升)。兼顾计算效率的自我引导工程: 评估器(Evaluator)和修正器(Refiner)如果直接用庞大的Teacher模型会导致RL开销爆炸。本文巧妙通过蒸馏策略,让一个 3B 级别的学生模型完成了 Scoring 和 Query Refinement 的脏活累活。消融实验证明,虽然用大模型做 Evaluator 能稍微涨点(<1% F1),但耗时会增加 5 倍,凸显了工程设计的权衡智慧。Reward Shaping 的优雅设计: 阶段 3 中的 Reward 设计极其合理,即 $\gamma \cdot n_{\text{wrong}}$ 惩罚冗余操作,$\gamma \cdot n_{\text{correct}}$ 鼓励有效的中间探索。这种 Dense Process Reward 有效避免了传统稀疏 Reward 导致的训练崩溃(Collapse),在 RLHF 实践中非常值得借鉴。