Enhancing LLM-based Search Agents via Contribution Weighted Group Relative Policy Optimization
中文标题:通过贡献加权的分组相对策略优化增强基于 LLM 的搜索智能体
作者:Junzhe Wang, Zhiheng Xi, Yajie Yang, Qi Zhang 等
机构:复旦大学 NLP 实验室,上海人工智能实验室
📄 查看 ArXiv 原文
研究背景与痛点
搜索型 LLM Agent 的核心难题不是“会不会搜”,而是“该把成功归功于哪一步搜索”。传统 outcome-only RL 只有最终对错,无法区分关键检索动作与无效噪声动作;而直接做 process reward 又极易受 judge 噪声影响,训练非常不稳。
核心贡献
- 提出 CW-GRPO,把过程监督从“直接奖励”改成“优势重分配缩放因子”。
- 同时衡量 retrieval utility 与 reasoning correctness,只奖励真正高贡献轮次。
- 证明多轮搜索里贡献高度集中于少数关键步骤。
具体案例剖析
输入:“2012 年 Notre Dame 校长是什么时候开始任期的?”
训练前输出:模型搜到 president-elect in 2004 后误答 2004。
训练后输出:模型并行发起多个 query,检索到 “term started in 2005”,最终正确回答 2005。
这个 case 说明高质量 RL 不只是提升答案准确率,而是改变 Agent 的搜索策略形态:更并行、更抗干扰、更会找决定性证据。
方法论与技术实现
轨迹级优势先按 GRPO 方式计算:
$$A_i^O = \frac{R_i - \mathrm{mean}(R)}{\mathrm{std}(R)}$$
对每轮动作 $t$,分别估计检索效用 $u_i^t$ 与推理正确性 $v_i^t$,再构成联合贡献指标 $p_i^t=u_i^t\cdot v_i^t$。之后通过 softmax 形成轮次权重 $c_i^t$,最后把轨迹优势重分配成 $A_i^t = A_i^O \cdot c_i^t \cdot (T_i-1)$。这个设计保留了 outcome anchor 的稳定性,同时获得了 process-level credit assignment。
实验设置与结论分析
论文在知识密集型、多跳搜索任务上验证了 CW-GRPO。结果显示,它系统性优于传统 GRPO 与显式 process-reward baseline,尤其在 multi-hop benchmark 上收益更大。消融实验也表明:仅看检索、不看推理,或仅看推理、不看检索,都会明显退化。
关键技术亮点分析
- 非常像工业界真正需要的“稳健 process supervision”。
- 把 judge 从绝对裁判降级为相对分配器,工程上更抗噪。
- 对 Search Agent、Deep Research Agent、Web Agent 都有普适意义。
LiteResearcher: A Scalable Agentic RL Training Framework for Deep Research Agent
中文标题:LiteResearcher:面向深度研究智能体的可扩展 Agentic RL 训练框架
作者:Wanli Li, Bince Qu, Bo Pan, Jianyu Zhang, Zheng Liu, Pan Zhang 等
机构:浙江大学,Simplex AI,香港理工大学
📄 查看 ArXiv 原文
研究背景与痛点
Deep research agent 最难的不是 reasoning,而是训练环境。真实互联网太慢、太贵、太不稳定;纯合成环境又不够像真实 Web。没有一个既低成本又高保真的虚拟世界,Agentic RL 很难真正扩展。
核心贡献
- 构建 Lite Virtual World,把真实 Web 搜索动态搬到本地可扩展环境中。
- 设计数据与语料共扩展流程,持续丰富训练世界。
- 提出课程式 GRPO 训练,让小模型也能在 deep research 任务上打出大效果。
具体案例剖析
输入:一个需要跨多个来源验证经济数字的问题。
系统机制:通过 source masking 刻意移除答案原始页面,逼迫 Agent 通过 aggregation、cross-verification、enumeration 等策略自行还原证据链。
输出:Agent 不能“背答案”,只能“真正搜出来”。这让训练信号更像真实 deep research,而不是网页记忆测验。
方法论与技术实现
论文把本地 Search Engine、Local Browser、Difficulty-aware filtering 和 On-policy GRPO curriculum 组合成统一飞轮。样本先通过 pass@k 难度筛选,再进入课程式 RL。其目标本质仍是组相对策略优化,但关键突破在于“环境工程”而不是单点 loss 改动。
对给定 query 与一组候选轨迹,GRPO 通过组内相对奖励构建优势并更新策略,这里省略复杂细节,重点在于:长轨迹 Agentic RL 对 policy lag 极度敏感,因此论文强调 pure on-policy 训练。
实验设置与结论分析
LiteResearcher-4B 在 GAIA、Xbench、Frames 等 deep research benchmark 上表现非常强,甚至追平或超过若干商业系统。更有意思的是,RL 之后轨迹变短了、无效交互少了,说明模型学到的是更高效的研究策略,而不仅是更长的 CoT。
关键技术亮点分析
- 说明环境质量对 Agent RL 的价值可能比参数量还大。
- source masking 是很聪明的防捷径机制。
- 对企业内部 deep research / knowledge worker agent 训练很有启发。
Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
中文标题:Agent-World:通过扩展真实世界环境合成推进通用智能体自我演化
作者机构:中国人民大学,字节跳动 Seed
📄 查看 ArXiv 原文
研究背景与痛点
真正的通用 Agent 训练不能只靠静态 benchmark 或 LLM 幻想出来的 toy world。它需要真实工具、真实数据库、真实状态更新,以及能不断诊断弱点、自动生成新环境与任务的进化式训练闭环。
核心贡献
- 提出 Agent-World,把“环境合成”本身变成一个可扩展系统工程。
- 自动发现数据库、合成可执行工具、再生成可验证任务。
- 引入 diagnosis agent,让训练环境随模型弱点持续进化。
具体案例剖析
输入:一个电商退货长任务,需要身份校验、订单筛选、商品级确认、退款路径选择与状态写回。
输出轨迹:Agent 连续调用多项工具,逐步追踪状态,并最终写回正确数据库操作。
这个例子很好地说明:很多 Agent 错误不是“不会推理”,而是“不会在长任务里持续维护世界状态”。
方法论与技术实现
方法分为两层:一层是 Agentic environment-task discovery,从网络和真实资源中自动构建数据库、API、任务与验证器;另一层是 continuous self-evolving training,使用可验证 reward 做多环境 RL。
形式上,它把 open-world agent 任务压缩成可执行验证问题:要么由 judge + reference 规则进行图任务判断,要么由代码执行器验证最终状态是否正确,从而把开放式任务转换为可训练的 verifiable RL。
实验设置与结论分析
在 23 个高难 Agent benchmark 上,Agent-World 系列模型展现出很强的跨环境泛化能力。更重要的是,性能会随着环境数量与自进化轮次提升而近似线性改善,这意味着“环境 scaling law”可能是 Agent 时代非常关键的新轴。
关键技术亮点分析
- 把“训练数据”升级成“训练世界”。
- 把 open-world 任务转写成可验证奖励,是非常强的 RL 设计。
- Diagnosis-driven evolution 很像给 Agent 配了一个自动教练系统。
Bilevel Optimization of Agent Skills via Monte Carlo Tree Search
中文标题:基于蒙特卡洛树搜索的智能体技能双层优化
作者:Chenyi Huang, Haoting Zhang, Jingxu Xu, Zeyu Zheng, Yunduan Lin
机构:NUS, UC Berkeley, CUHK
📄 查看 ArXiv 原文
研究背景与痛点
Agent skill 不只是 prompt,而是一个多文件、多资源、多约束的结构化软件包。优化它时,结构修改与内容修改强耦合,搜索空间又巨大,用传统 prompt tuning 或简单代码优化都很难做对。
核心贡献
- 首次把 Agent Skill 优化建模成 bilevel optimization。
- 外层用 MCTS 搜结构,内层做内容对齐与 refinement。
- 用悲观估计与置信下界控制 LLM 评估噪声。
具体案例剖析
输入:一个 ORQA 任务技能包,原本把任务分诊逻辑散落在 references 文件里。
优化动作:把关键 triage checklist 内联到主 SKILL.md,并重写输入契约与执行步骤。
输出效果:优化后的 skill 更自包含、更稳定,测试准确率从 0.90625 提升到 0.9375。
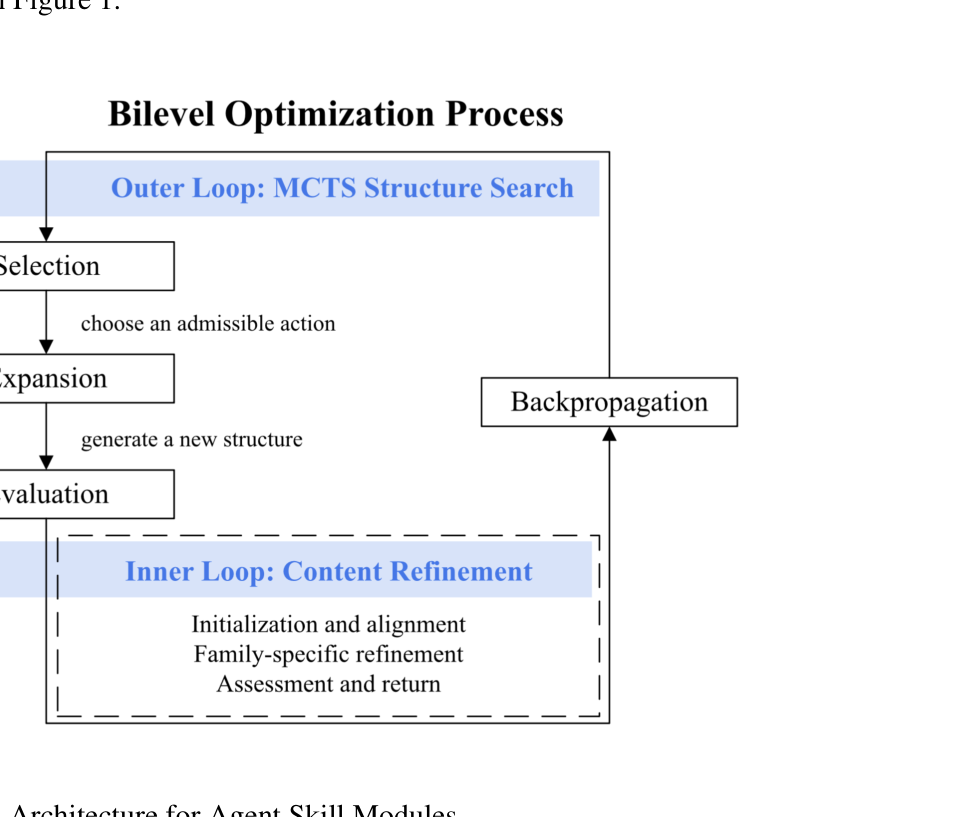 图注:外层 MCTS 负责探索 Skill 结构变体,内层在固定结构下进行内容桥接、对齐与局部重写,最终再把 reward 回传到树搜索。
图注:外层 MCTS 负责探索 Skill 结构变体,内层在固定结构下进行内容桥接、对齐与局部重写,最终再把 reward 回传到树搜索。
方法论与技术实现
把 skill 表示为 $S=(\theta, \phi)$,其中 $\theta$ 是结构配置,$\phi$ 是内容实例化。整体目标是:
$$\max_{\theta \in \Theta} \max_{\phi \in \Phi(\theta)} R_{S_0}(\theta,\phi)$$
MCTS 节点表示结构状态,动作表示增加、删减、重排、迁移模块。内层 refinement 则负责把旧内容桥接到新骨架,并使用 LCB 等悲观策略避免假提升。这种“结构搜索 + 内容重写”的解耦方式,对未来复杂 Agent workflow 优化非常重要。
实验设置与结论分析
论文在 ORQA 上验证该框架,结果证明:对 Agent 来说,结构重排本身就会显著改变认知执行路径,而不是只有 wording 才重要。MCTS 能有效找到高价值的结构变体。
关键技术亮点分析
- 把 Skill 视为可优化的“认知架构”,这点很新。
- 结构搜索比纯 prompt rewrite 更接近真实 Agent 工程。
- LCB 机制对防止自迭代退化很有现实价值。
AgentGL: Towards Agentic Graph Learning with LLMs via Reinforcement Learning
中文标题:AgentGL:通过强化学习实现 LLM 的智能体图学习
作者:Yuanfu Sun, Kang Li, Dongzhe Fan, Jiajin Liu, Qiaoyu Tan
机构:纽约大学上海分校,清华大学
📄 查看 ArXiv 原文
研究背景与痛点
现有 Agent 系统擅长处理非结构化文本,却不擅长在原生图结构上做动态探索。GraphRAG 会丢掉一部分真实拓扑信息,传统 GraphLLM 又太静态,无法像真正 Agent 一样按需检索图邻域与结构证据。
核心贡献
- 提出 Agentic Graph Learning 范式。
- 设计 graph-native tools:1-hop/2-hop、结构显著性搜索、图密集检索等。
- 结合两阶段 RL 和 graph-conditioned curriculum learning。
具体案例剖析
输入:判断两个 Reddit 鸟类帖子节点是否存在边。
中间过程:Agent 先分析语义相似性,再主动调用 1-hop 工具寻找共同邻居,观察到多个强一致的共邻节点。
输出:最终预测两节点有连接,并且在证据足够后主动终止搜索。相比纯文本相似度方法,这更像是在“图上取证”。
方法论与技术实现
论文定义了图上的动作空间,包括局部邻居查询、全局结构显著性搜索、语义密集检索等。RL 目标可以写成:
$$\mathcal{J}(\theta)=\mathbb{E}_{\tau\sim \pi_\theta}[\mathcal{R}(\hat y, y^*)-\beta D_{KL}(\pi_\theta\parallel \pi_{ref})]$$
第一阶段用 coverage reward 鼓励工具探索,第二阶段再抑制 search overuse,并配合图先验定义课程难度。这样既教会模型“怎么搜”,也教会模型“何时停”。
实验设置与结论分析
在节点分类、链路预测与 zero-shot 泛化上,AgentGL 相比 GraphLLM、GraphRAG、Search-R1/O1 类 baseline 都有明显提升。尤其在 OOD 设置下,说明它学到的是图上的搜索策略而不是数据集套路。
关键技术亮点分析
- 把图任务从静态表征问题改造成动态 Agent 问题。
- 对“过度搜索”给出很实用的 RL 抑制机制。
- 图先验驱动 curriculum 的想法非常干净、很工程化。