MATH TAKES TWO: A TEST FOR EMERGENT MATHEMATICAL REASONING IN COMMUNICATION
中文标题:数学需要两个人:通信中涌现的数学推理测试
作者:Michael Cooper & Sam Cooper
机构:Cooper Cognitive
会议标签:HCAIR Workshop (ICLR) 2026
1. 研究背景与核心痛点
近年来,大语言模型(LLMs)在数学推理Benchmark(如GSM8K, MATH等)上取得了令人瞩目的成绩。然而,学界对模型是否真正掌握了数学推理能力 (Mathematical Reasoning) 仍存在巨大争议。很多研究指出,LLMs的亮眼表现可能更多归功于对海量形式语法的统计模式匹配 (Statistical Pattern Matching),而非基于第一性原理的抽象构建能力。它们在复杂的组合推理(Compositional Reasoning)及分布外(OOD)外推任务上经常发生灾难性失效。
从人类演化史来看,数学并非凭空产生,而是与“精确交流”的刚需共同进化 (Co-evolved with communication)。例如,美索不达米亚平原上的早期算术与泥板上的农业记账、土地测量息息相关。“八个敌人正在靠近”——用抽象符号表达数量,比口头重复“敌人”八次具有压倒性的信息压缩与生存优势。数学本质上是基于物理直觉的高度压缩和抽象。
痛点:现有的评估体系大多依赖于已经成型的、人类定义好的数学惯例(如阿拉伯数字、加减号语义)。我们缺乏一个真正的环境来测试:如果完全不输入任何人类语言和数字系统的先验,神经网络 Agents 能否在纯粹的通信压力下,“涌现”出具有泛化性的算术概念和符号协议?
2. 核心贡献
- 提出了一个开创性的Benchmark——Math Takes Two: 彻底摒弃预先设定的数学语料,要求两个没有任何数学先验的 Agent(Speaker 和 Listener),为了解决视觉基准任务,从零开始(From scratch)发明并协商出一套共享的离散符号系统。
- 针对组合泛化 (Compositional Generalization) 的严苛测试: Benchmark 引入了强 OOD 阶段,不仅要求 Agent 能够进行符号映射,还必须具备系统性地向未见过的物体、数量组合进行外推(Extrapolation)的能力。
- 提供了人类与模型的基准对比 (Human & Model Baselines): 对 10 对人类被试进行了相同的无先验测试,并与基于
Gumbel-Softmax的符号自编码器(Symbolic Autoencoder)和视觉-语言 Transformer 进行了深入对比,揭示了当前神经网络架构在“涌现算术推理”上的巨大能力鸿沟。
3. 具体案例剖析 (Case Study: 早期人类式符号涌现游戏)
该 Benchmark 的核心机制类似于经典的 “Bag-Select” 多智能体通信游戏,但融入了数字与几何的空间阵列。游戏规则如下:
- 输入限制: Speaker 看到一张带有一定数量和特定形状 $m \times n$ 阵列的图片。
- 通信瓶颈: Speaker 只能向 Listener 发送一条最多由 8 个字符组成的离散消息。词表被严格限制在 8 个 Token:
[A, B, C, 0, 1, 2, +, *]。(这只是一个无意义的 token 集合,模型不能预设 1 就代表数字 1)。 - 动作选择: Listener 没有看过原图,仅凭这最多 8 个字符的消息,需要在 4 张候选图片中挑选出正确的 Target 图片。
人类玩家表现剖析:
在测试中,人类通过沟通,自发演化出了高度抽象的通信协议以对抗 OOD 问题。人类通常采用以下三种策略:
- 决策树编码 (Decision Tree Encoding): 第一个字符代表“最多的形状是什么”,第二个代表“横向最多数量”等。
- 索引式编码 (Index-Based Encoding): 严格划分消息槽位,前两位记录形状类型,后两位记录行列数。
- 程序化/数学重构 (Programmatic Encoding): 这是最令人惊叹的!有的人类被试群体甚至完全通过对视觉特征的观察,重新发明了三进制系统 (Base-3 system),并使用类似
形状标识符 + 三进制数字的组合,以极强的数据压缩率完美地解决了测试集中的未见数量 OOD 问题。
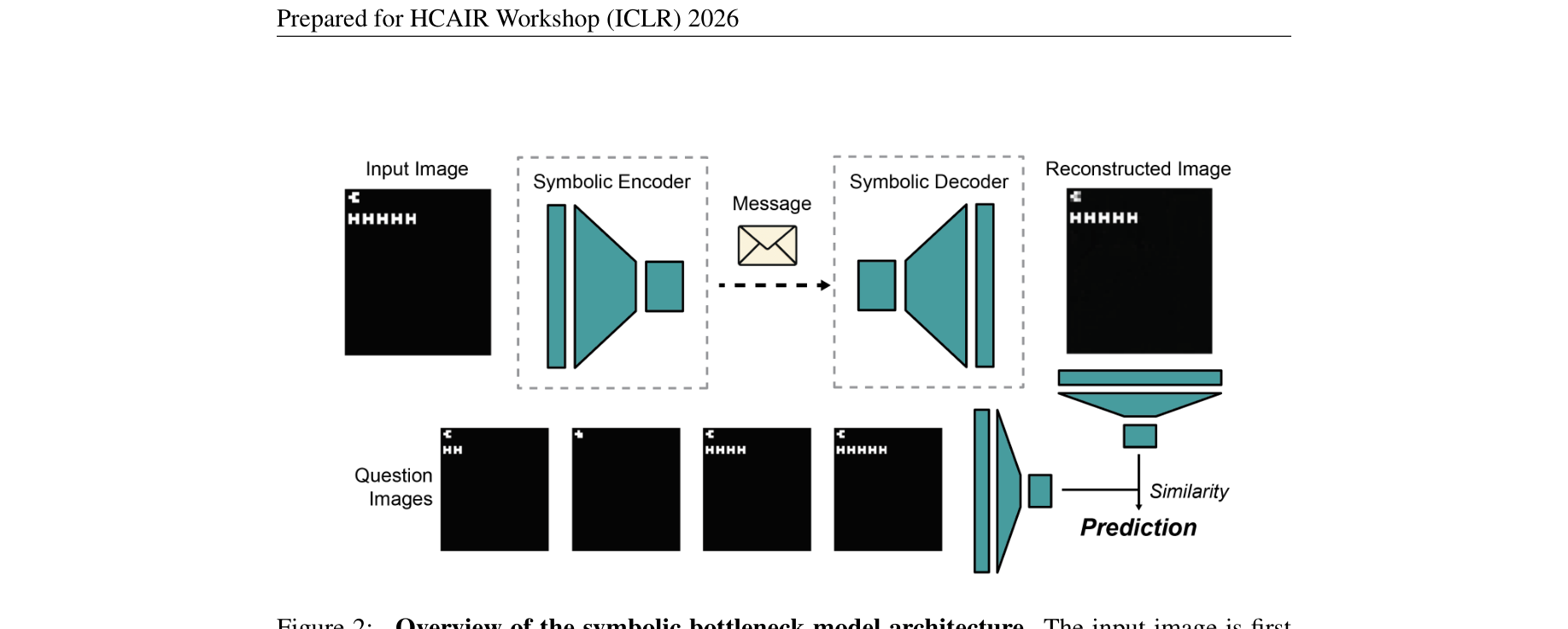
为了探究现代深度学习架构在该基准上的表现,作者引入了基于 符号通信瓶颈 (Symbolic Bottleneck) 的模型架构:
4.1 基于 Gumbel-Softmax 的离散通信通道
在 Speaker 到 Listener 的通信中,必须切断梯度的连续传递,模拟现实物理世界的离散符号语言。模型利用 Gumbel-Softmax 重参数化技巧:
Speaker 的 Encoder 将卷积特征图展平后,映射为固定长度 $L=8$ 的序列,每个位置服从类别大小为 $K=8$ 的分类分布。经过采样后,得到离散的消息矩阵 $M \in \mathbb{R}^{B \times L \times K}$。在训练阶段,参数 $\tau \to 0$ 时逼近 one-hot 离散表示,同时保持梯度可微。
4.2 Symbolic Autoencoder 与 Similarity Network
模型首先以自监督的方式训练重构误差:Speaker Encoder 生成离散 token,Listener Decoder 将其重构回与原输入维度相同的 Feature Map,优化均方误差 (MSE)。
之后,引入一个独立的 相似度网络 (Similarity Head) 进行 4-way 选择任务。将 Listener 重构出的特征向量 $f_{\text{target}}$ 与通过图像编码器提取的 4 个候选图像特征向量 $f_{q_i}$ 进行 L2 归一化后的余弦相似度计算:
$$ s_i = \cos(f_{\text{target}}, f_{q_i}) \quad \text{for } i \in \{1 \dots 4\} $$
最终通过 Cross-Entropy Loss 对分类结果进行端到端优化或仅微调 Similarity Head。
4.3 Symbolic Transformer Baseline
除了卷积网络外,作者还实现了一个将自编码器 Bottleneck 替换为 Transformer Decoder (Image-to-Symbol) 和 Transformer Encoder (Symbol-to-Image) 的架构,以赋予模型更强的序列上下文建模能力。
5. 实验设置与结论分析
实验协议:分为 Preconditioning (学习空间,无监督)、Practice (有监督,有限的新物体/数字)、Test (无反馈,完全未见过的 OOD 组合)。实验严格禁止使用在大规模文本上预训练的 LLM(为确保是“从零涌现”)。
核心结果对比:
| Player / Model | 总体准确率 (Test) | OOD 形状 | OOD 数量 | 双重 OOD (形状+数量) |
|---|---|---|---|---|
| Human Baseline | 87% | 84.4% | 73.1% | 69.2% |
| Symb Conv AE (Unfrozen) | 72% | 55.6% | 69.2% | 38.5% |
| VL Transformer | 65% | 46.7% | 50.0% | 30.8% |
关键结论分析:
- 人类的降维打击: 人类在测试阶段整体能维持 87% 的准确率,说明人类从一开始构建语言符号时,就是奔着“生成式外推规律 (Generative Rules)”去的,具有内在的组合性。
- 模型的惨败 (尤其在极端 OOD): 最优的卷积模型在只遇到 OOD 数量或 OOD 形状时勉强能有 50-60% 的泛化,但当同时面临新形状+新数量组合时,准确率断崖式下跌至 38.5%(随机猜测为25%)。这暴露出现有架构依然只是在隐式空间做局部插值(Local Interpolation),而未能解耦 (disentangle) “数量”与“形状”的独立正交概念。
- 任务目标的错位: 有趣的是,实验发现在一起端到端训练相似度分类任务(Unfrozen),虽然提高了 Practice 阶段的表现,但却降低了 Test 阶段(OOD)的外推能力。这暗示过早地让通信符号去拟合特定任务的捷径(Shortcut),反而抑制了通用基础抽象概念的形成。
6. 关键技术亮点与未来启示
- 从“学习”到“涌现”的视角切换: 传统对模型数学能力的评测类似于“考试做题”。而本工作回归本源,将“纯粹的视觉-概念映射与交流压缩机制”视为数学产生的原动力。这为 AI-Scientist 或更底层泛化模型的设计提供了绝佳的思想实验场。
- 外部记忆机制 (External Memory) 的必要性: 论文中提到,人类在完成该任务时大量依赖外部纸笔打草稿(构建符号映射表)。对比近期 Bengio 团队等关于 LLM 系统 2(System 2)思考的观点,限制模型的瞬时工作记忆(Working Memory),强制其利用外部符号寄存器(Symbolic Registers)进行多跳读写,可能是攻克此类需要坚实组合泛化任务的必要架构革新。
- 不确定性建模能力: 人类在 Practice 阶段会有意设计能够容纳未知情况的 Fallback 规则(如预留特殊符号用于未见情况)。赋予深度学习智能体对环境分布偏移(Distribution Shift)的主动不确定性感知,是通向 Robust Emergent Communication 的重要一步。