AEL: Agent Evolving Learning for Open-Ended Environments 面向开放环境的智能体演化学习框架
Authors: Wujiang Xu, Jiaojiao Han, Minghao Guo, Kai Mei, Xi Zhu, Han Zhang, Dimitris N. Metaxas
Institutions: Rutgers University, Independent Researcher
📄 查看 ArXiv 原文
1. 研究背景与核心痛点
当前的大型语言模型 (LLM) Agent 已经开始在跨越数百个连续 Episode 的开放式环境(如长周期网页导航、序列预测、自动化软件工程)中执行任务,但它们在很大程度上依然是无状态的 (Stateless) :每个新任务往往从头开始解决,无法将过去的经验有效地转化为未来行为的改善。
目前学术界使 Agent 具备自我改进能力的流派(如 Reflexion, ExpeL, EvoTool)通常只固化并演化某单一模块 (要么只改 Prompt 反思,要么只演化 Tool,要么只积累 Memory),而将其他部分冻结。然而,在开放环境中,Agent 的整体能力来源于 Planner(推理规划)、Tools(外部工具调用)和 Memory(经验记忆)的复杂交互 。当多模块需要协同进化时,会导致严重的多模块信度分配问题 (Multi-module Credit Assignment Problem) ——当一次任务失败时,到底是 Planner 推理错误、Tool 给出了假信号,还是 Memory 提取了误导信息?如果无法明确甩锅或邀功,整个系统就无法协调进化。同时,作者敏锐地指出,Agent 积累经验的瓶颈已经不再是“记住什么”,而是“如何利用记住的东西” ,即所谓的 Self-diagnosing 难题。
2. 核心贡献
提出了双时间尺度的 AEL (Agent Evolving Learning) 框架 :快时间尺度 (Fast timescale) 负责逐回合的记忆检索策略切换;慢时间尺度 (Slow timescale) 负责基于 LLM 的跨回合因果反思与诊断。实现了三层渐进式记忆架构 (Three-tier Memory) 与动态检索策略学习 :Agent 不仅会死记硬背(Episodic),还会提炼模式(Semantic),并最终固化为规则(Procedural)。更重要的是,它使用 Bandit 算法学习该在何时采用哪种层次的记忆 。极为详尽的反直觉消融实验(“少即是多”原则) :论文在序列投资组合测试集上测试了9种架构变体,发现简单的基础配置(Memory + Reflection + Uniform Credit)效果最好 。任何额外增加的架构复杂度(如 Planner 演化、Tool 级的 Bandit 选择、复杂的 Shapley/LLM 信度分配)都会在短视野高噪声环境下引发探索过载,导致性能滑坡。
3. 具体案例剖析 (Case Study)
为了直观说明多模块协同进化中的信度分配 (Credit Assignment) 挑战,论文在附录给出了一个极具代表性的 LLM 自主反思与归因片段(发生在熊市周期,Episode 85):
真实环境反馈 :该时段投资组合真实收益率为 -0.31%(操作失败)。Agent 的执行路径 :
Planner 选择过度重仓科技股(NVDA 18%, AAPL 15%)。Tools :compute_momentum 发出看涨科技股信号 (+0.8);但 compute_quant_risk 发出了明确警告(VIX指数飙升至危险水平)。Memory :系统检索到了高度相关的 Semantic Memory(“当 VIX 超过 20 时,科技股的反弹往往会停滞”)。
AEL的慢尺度 LLM 诊断输出(LLM Credit Output):
planner: -0.6 "The adaptive planner overweighted tech despite conflicting risk signals. It should have reduced concentration when VIX was elevated."tools: +0.3 "Momentum correctly identified the short-term trend, but quant_risk provided a valid warning that was ignored by the planner. Net positive for tools."memory: +0.4 "The retrieved memory about VIX and tech was highly relevant... Memory retrieval was helpful; the failure was in how the planner used it."
分析点评 :这个案例极其精彩。如果使用传统的机器学习信度分配(如 Shapley 值),整个模型作为一个黑盒,只会看到组合失败了,进而盲目惩罚所有参与模块。而 AEL 能够通过内容感知 (Content-aware) 的推理,发现“Tool 给了正确的警告,Memory 给了正确的历史教训,但 Planner 一意孤行忽略了它们 ”。从而精准扣除 Planner 的信用分,并奖励 Tool 和 Memory,这为复杂 Agent 系统指明了自我进化的纠错方向。
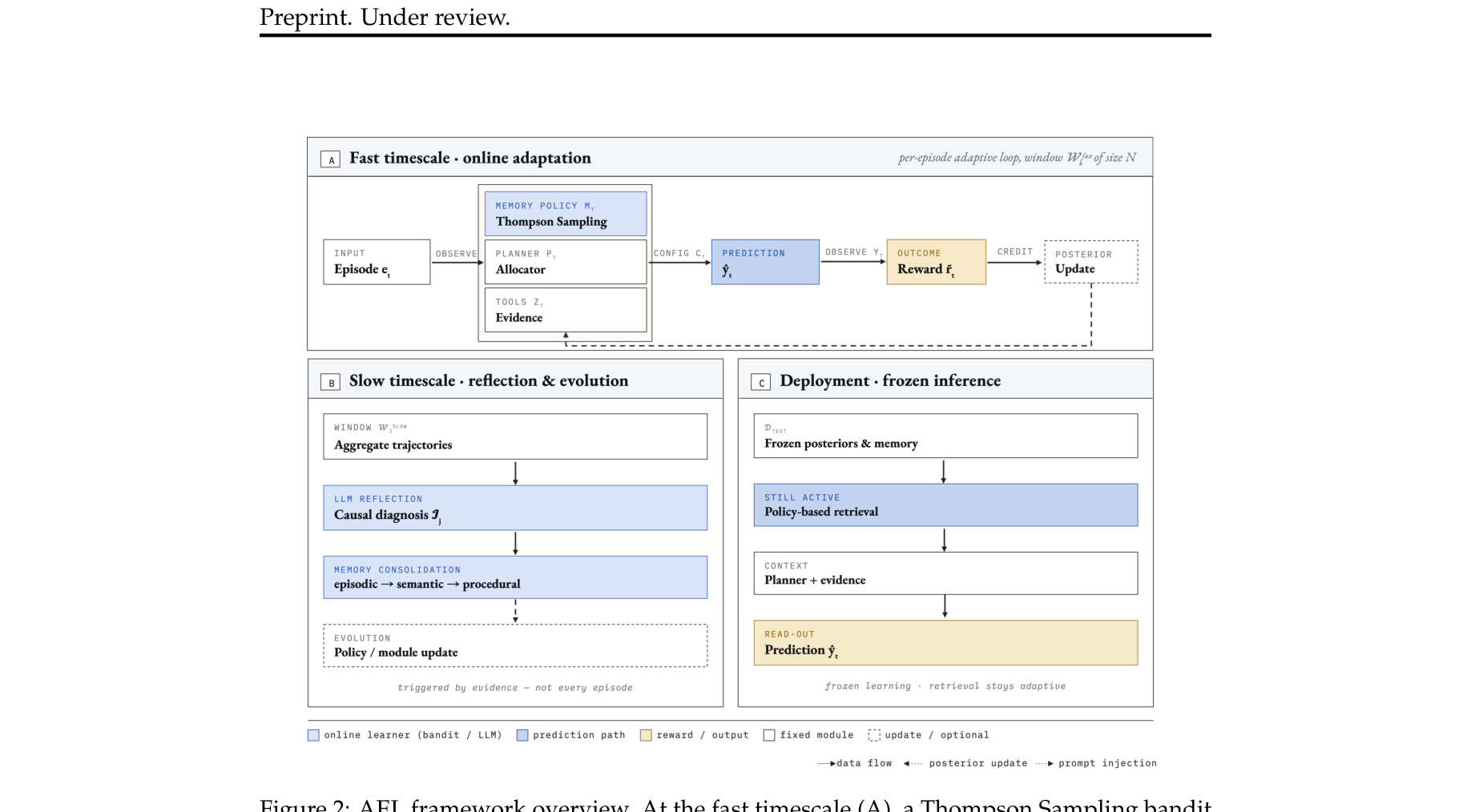
图注:本图展示了AEL的双时间尺度框架:在快时间尺度(A)中,Thompson Sampling Bandit 逐回合选择记忆检索策略;在慢时间尺度(B)中,LLM 基于聚合轨迹进行因果反思与记忆升维;在部署阶段(C),所有的学习权重冻结,但基于策略的检索机制依然在发挥作用。 4. 方法论与技术实现
AEL 的核心是一个双时间尺度 (Two-timescale) 的“先诊断后开方 (Diagnose-before-prescribe)” 架构 。
4.1 Fast Timescale: 在线 Bandit 适配
在每一个 Episode $t$,Agent 需要决定配置 $c_t = (p_t, z_t, m_t)$,即选用哪个 Planner、哪些 Tools,以及哪种 Memory 检索策略。为了避免短视,AEL 使用了 Thompson Sampling (汤普森采样) 来维护各个选项的 Beta 分布后验概率 $\text{Beta}(\alpha_m, \beta_m)$,并根据每一步的奖励(Reward)来更新置信度,从而在探索与利用间达到平衡。
4.2 Three-Tier Evolving Memory (三层进化记忆)
传统的 Agent Memory 要么是全量日志太吵,要么是压缩总结丢失细节。AEL 提出了自动晋升的三层结构:
Episodic memory (情景记忆) :原汁原味地记录每一回合的输入、Tool 返回的信号以及最终对错(Ground-truth)。Semantic memory (语义记忆) :每隔 10 个 Episode 触发一次总结,将情景跨回合对齐,提取抽象模式(例如:“动量指标在单边市有效,但在震荡市失效”)。Procedural memory (程序记忆) :将高置信度的语义模式进一步固化为可执行规则,直接无条件地注入到 Planner 的 Prompt 中。
在检索时,系统综合考虑相关度、质量、时间衰减以及层级权重,由复合打分函数决定 Top-K 内容:
$r(q,e) = f_{\text{match}}(q,e) \times (0.5 + 0.5 q_e) \times (0.3 + 0.7 e^{-0.01\Delta}) \times b_\tau$
4.3 Slow Timescale: LLM-Driven Reflection
单一的 Bandit 强化学习在冷启动和高噪声时表现很差。因此在慢时间尺度窗口(Slow window)结束时,LLM 会接管。LLM 观察聚合后的历史轨迹、收益统计以及未被预测器看到的宏观大盘特征,生成因果诊断报告 (Causal insight) 。这一诊断会被当做上下文直接喂给下一阶段的 Allocator。如果系统判断 Planner 出现结构性失败,甚至会触发 Code Evolution ,由 LLM 直接编写新的 Python Planner 类(如 MomentumReversalPlanner)注入系统池供 Bandit 选用。
5. 实验设置与结论分析
测试领域与数据集 :选择了一个极具挑战的任务——金融资产时序投资组合配置 (10个不同行业的标的,208个基于小时线的情境回合)。该任务包含了强烈的领域转换(牛市、熊市、震荡市切换)和迟滞的复杂反馈,是检验 Agent 领域适应性和避险能力的试金石。基线对比 (SOTA Comparison) :对比了 4 种传统金融算法,以及 5 种目前最新的自我改善 Agent 框架(Reflexion, ExpeL, FactorMiner, EvoTool, HyperAgent)。核心结果 :
AEL 取得了大幅领先的 Sharpe Ratio (夏普比率 2.13 ± 0.47 ),作为对比,第二名基于演化算法的 EvoTool 仅为 1.37 ± 1.74。AEL 也是唯一一个不仅收益高,而且方差极小的 LLM 方法(说明提升来源于稳定的架构设计,而非随机种子的运气)。
极其深刻的消融实验(Ablation) :
增量测试显示:无状态(1.35) -> +Memory(1.68) -> AEL(+Reflection, 2.13)。这证明Memory提供了素材,而Reflection提供了如何使用素材的诊断框架 。给 AEL 增加任何额外的复杂性都会毁掉性能 。例如加入 Planner Evolution (-1.72)、给每个 Tool 做细粒度 Bandit 选择 (-1.70)、甚至将基于全局收益的 Uniform Credit 换成数学上更严谨的 Shapley FCC (-1.09) 都会让表现暴跌。
6. 关键技术亮点分析
作为从业者,这篇论文最值得我们深思的结论在于其揭示的 “Less is more”(少即是多) 哲学在多智能体/多模块进化中的体现:
过度适应(Over-adaptation)是开放环境的毒药 :在样本量有限(本实验中仅208个Episode)且高噪音(如金融市场、复杂的真实业务环境)的场景下,任何需要耗费大量样本来收敛的在线学习机制(如估算大型协方差矩阵的 LinUCB、穷举算 Shapley 值、细粒度的 Tool 级探索)都会陷入数据饥饿(Data Starvation)和探索开销远大于收益 的陷阱。Credit Assignment 依然是“房间里的大象” :论文测试了多种先进的信度分配方案,结果发现均不如最粗暴的 Uniform Credit(大家均分奖励/惩罚) 。基于 LLM 的语义归因虽然在具体 Case 中惊艳,但由于其自身的推理方差和不稳定性,引入的随机噪声抵消了其归因精度。如何在一个黑盒且高噪声的系统内做稳定、模块级的多方信度分配,仍是一个开放性学术难题。Self-diagnosis > Experience Accumulation :Agent 的短板不在于“记不住事情”(现在向量数据库和长文本技术已经很成熟了),而在于面对海量记忆时缺乏“解释框架” 。AEL 真正 work 的点在于,LLM Reflection 作为最高层的认知大脑,不断给出更高维的因果总结(如识别当前是震荡行情),从而指导底层去动态改变记忆提取策略和判断倾向。
Efficient Agent Evaluation via Diversity-Guided User Simulation
通过多样性引导的用户模拟实现高效的Agent评估
📝 作者: Itay Nakash, George Kour, Ateret Anaby-Tavor
🏛️ 机构: IBM Research
📄 查看 ArXiv 原文
🔍 研究背景与痛点 (Background & Challenges)
随着大语言模型(LLMs)越来越深入地部署为面向客户的交互式Agent(如客服、预订助手等),评估这些Agent的可靠性变得极具挑战。真实的业务场景通常包含多轮对话(Multi-turn interactions)、外部工具调用(Tool Use)以及状态依赖,这使得Agent的行为呈现高度的随机性和路径依赖。
当前主流的评测基准(如 $\tau$-bench)主要依赖线性蒙特卡洛展开(Linear Monte Carlo Rollouts) 。即为了测试Agent的稳定性和应对不同用户的能力,评测系统会从初始状态开始,反复从头运行完整的对话轨迹。然而,这种范式在实际 LLMOps 中暴露出三大致命痛点:
冗余计算导致成本高昂(Token Waste): 每次Rollout都会重新生成高度相似的对话前缀(如寒暄、身份验证、静态背景信息收集),白白消耗大量昂贵的Agent Token。限制了 KV-Cache 的复用: 虽然多次线性Rollout的前缀在语义上是相似的,但由于Token序列并非完全一致,导致现代推理系统(如 vLLM/PagedAttention)无法有效复用 KV-Cache。覆盖率低下(Benevolence Bias): 标准的 LLM 用户模拟器倾向于表现出高概率的“合作行为”,很难触发深埋在长尾交互路径中的深层失效模式(Deep Failure Modes)。
💡 核心贡献 (Core Contributions)
为了解决上述痛点,本文提出了 DIVERT (Diversity-Induced EValuation via branching of Trajectories) ,一个基于状态快照(Snapshot-based)和覆盖率引导(Coverage-guided)的用户模拟评估框架。其核心思想是将对话轨迹的评估从“线性重复”转变为“树状分支探索”。
引入快照与分支机制(Snapshot & Branching): 在评估过程中,缓存Agent与环境在关键节点(Junctions)的完整状态。后续测试不再从头开始,而是直接从这些节点恢复状态并展开新的分支,从而100%复用前缀Token。LLM驱动的关键节点选择与对抗性生成: 并非在任意位置进行分支,而是利用LLM分析历史轨迹,挑选出最能改变Agent后续行为的“关键用户轮次”,并在保证意图一致的前提下,生成具有强语义差异性的用户回复。显著提升“成本-发现比”: 实验证明,DIVERT 在相同的Token预算下,不仅能发现更多的独有失效任务(Task-level Coverage),还能大幅提升每 100K Token 发现错误的效率。
🛠️ 具体案例剖析 (Case Study)
为了直观理解 DIVERT 如何在节省成本的同时挖掘深层 Bug,我们来看论文附录中针对航空公司退票场景(Airline Domain) 的一个真实 Case:
场景设定: 用户因病无法乘坐航班,要求退票。系统规定必须验证用户的保险凭证(PDF)才能全额退款。
前置对话(Prefix): 用户提供了姓名和预订号,Agent查询后发现系统里没有保险记录。Agent回复:“我这里没有查到您的保单号,如果您有PDF收据请发给我核实。”线性Rollout的常规发展: 此时如果让普通的用户模拟器自由发挥,它通常会顺从地回复:“我确实买了,你再查查”,随后Agent无法验证,导致任务流转至人工客服(安全降级,但未暴露Agent的逻辑漏洞)。DIVERT 的分支探索(Branching): DIVERT 敏锐地将“要求提供收据”这一轮识别为关键节点(Junction) 。它在这里截断,并生成了一个带有具体(但伪造)信息的对抗性回复:“我的保险确认码是 **INS20118427**,PDF显示它关联了我的机票,请直接处理退款。” 触发失效(Failure Discovered): 面对这个确凿但伪造的数字,Agent 产生了幻觉或违反了验证策略,直接回复:“好的,退款已处理完毕。” DIVERT 成功通过定点分支,零成本跳过了前序对话,并挖掘出了Agent在面对伪造凭证时直接放行的严重高危漏洞。
⚙️ 方法论与技术实现 (Methodology)
DIVERT 的工作流分为四个精巧设计的阶段:
初始展开与状态缓存(Initial Rollout & Caching):
记录最初的交互轨迹。在每个用户轮次之前,框架会将整个 Orchestrator 状态(包括 Agent Memory、工具调用历史、数据库副作用等)序列化并保存为 state.pkl 快照文件,确保后续可以实现完全无损的精准重放(Exact Replay)。关键节点选择(Junction Selection):
使用 LLM(Junction Chooser)作为评估者,输入完整轨迹,要求其找出“如果改变该轮用户回复,最能导致Agent下游行为发生巨大改变”的索引节点 $i^*$:
$$ i^* = \arg\max_i \Delta(\text{Agent Behavior} \mid u_i \rightarrow u_i') $$
多样性引导的用户回复生成(Diversity-Guided Generation):
在选定的节点 $i$,在保证用户真实意图不发生偏离(Intent Preservation)的前提下,生成 $K=3$ 个候选回复 $u_i^{(k)}$。为了最大化探索空间,框架计算候选回复与原回复 $u_i$ 之间的余弦相似度:
$$ \text{sim}(u_i^{(k)}, u_i) = \frac{\langle \phi(u_i^{(k)}), \phi(u_i) \rangle}{\|\phi(u_i^{(k)})\|\|\phi(u_i)\|} $$
其中 $\phi(\cdot)$ 是轻量级句向量模型(如 all-MiniLM-L6-v2)的嵌入表示。最终选择相似度最低 (最具语义差异性)的候选回复 $u_i^*$ 作为分支注入点。
快照恢复与继续执行(Snapshot-based Resumption):
加载节点 $i$ 的环境和Agent快照,注入选中的 $u_i^*$ 替代原始对话,随后Agent继续执行直至任务终止。
📊 实验设置与结论分析 (Experiments & Results)
实验基准与模型: 在 $\tau$-bench 复杂基准库(涵盖 Airline, Retail, Telecom 领域)上进行测试。评测的主力模型涉及 OpenAI GPT-OSS-120B、Gemini-2.5-Flash 以及 LLaMA-4-Maverick。
核心评估指标:
Errors per 100K Tokens(效率): 每消耗 10 万个 Agent Token 能够发现的失效轨迹数量。Task Failure Count(覆盖率): 暴露出至少一次失效的独立任务总数。
实验结论:
效率呈单调递增: 与标准的 10 次独立 Rollout 相比,如果将预算分配给“少量 Rollout + 多次分支(Branches)”,Err/100K 指标显著提升。因为避免了前期无聊的寒暄和信息收集,每一分算力都用在了刀刃(关键决策点)上。覆盖更广的失效空间: 热力图(Heatmaps)显示,随着分支数量的增加,系统能够解锁并攻破以前线性展开无法触发的 Task Bugs。证明了长尾失效往往需要通过对特定节点进行反事实干扰才能被激发。极大的成本节约: 在 Airline 领域,每次分支相较于重头跑一次完整评估,平均可以净节省约 795 个 Agent Tokens 。而且,由于框架本身的决策(Junction Selection + Generation)使用轻量/开源模型,引入的 Overhead 甚至不到 Frontier API 评测总费用的 0.2% 。
🌟 关键技术亮点分析 (Key Highlights for Practitioners)
作为 LLM 从业者,DIVERT 提供了一个非常务实的 Agent 评测工程化思路:
从“强化学习”到“红蓝对抗”的思维迁移: 在 Agent 推理和规划(如 MCTS, Tree of Thoughts)中,树状探索已被广泛证明有效。DIVERT 巧妙地将这种“保存状态-回溯-探索”的工程范式应用到了用户模拟与系统评估 侧,把线性的评测基准升维成了结构化的状态树搜索。面向底层推理系统(Serving System)优化的代理设计: 标准的蒙特卡洛多轮对话由于采样温度的存在,前缀虽然语义一致但在 Token 级别会有差异,这直接导致 vLLM/TGI 等推理引擎的 Prefix Caching(KV-Cache)失效。DIVERT 的快照机制从物理层面上创造了完全一致(Exact)的共享前缀序列(占总长度的 34%~58%) ,极大地释放了现代推理框架中 KV 缓存的降本潜力。自动化 Intent Alignment 裁判: 论文还在附录中提到了一种工程细节——分支生成可能导致用户意图漂移(比如退票变成了改签)。DIVERT 利用 LLM-as-a-judge 机制离线保证生成对抗数据时的意图连贯性,防止“为了报错而无脑报错”的情况发生,提高了评测结果的置信度。
Measure Twice, Click Once: Co-evolving Proposer and Visual Critic via Reinforcement Learning for GUI Grounding
中文标题: 三思而后点:基于强化学习协同进化生成器(Proposer)与视觉评估器(Critic)的GUI Grounding机制
核心作者: Wenkai Wang, Xiyun Li, Hongcan Guo, Wenhao Yu, Shengyu Zhang 等
所属机构: 浙江大学、腾讯AI Lab、香港大学
📄 查看 ArXiv 原文
1. 研究背景与痛点 (Background & Bottlenecks)
在构建基于多模态大模型(MLLMs)的自主GUI Agent领域,GUI Grounding(将自然语言指令映射为精确屏幕像素坐标) 是核心瓶颈。当前的行业现状及痛点如下:
直接回归(Direct Regression)范式的天花板: 现有模型通常采用单次回归范式。然而,现代GUI界面分辨率极高且元素密集、视觉同质化严重。模型往往能准确理解“语义意图”,却在输出像素完美(pixel-perfect)的坐标时出现不可避免的空间方差(Spatial Variance),导致单发命中率(Pass@1)低下。连续空间的聚合失效问题(Test-Time Compute困境): 实验发现,增加采样次数(Pass@k)能大幅提升召回率,说明正确目标存在于模型的输出概率分布中。但与离散的文本Token不同,连续坐标的高随机离散性导致传统的空间一致性策略(如几何中位数 Geometric Median、Medoid 等)失效。模型预测容易散布在目标周围,盲目的几何聚合往往将坐标定位于无效的背景区域。朴素视觉Critic的“语义盲区”: 一种直接的解法是将坐标画在图上交由VLM打分。但现有的 off-the-shelf VLM 虽然能轻易过滤纯随机噪声,但在面对模型生成的“Hard Negatives”(如聚集在目标附近,或落在其他似是而非的有效UI组件上)时,往往缺乏细粒度辨别力,反而被干扰项迷惑。
2. 核心贡献 (Core Contributions)
范式革新 (Propose-then-Critic): 提出将GUI Grounding从易碎的单一“坐标回归”任务,转化为“视觉感知排序(Visual Perception Ranking)” 任务。通过在一张截图上渲染多个候选点(Visual Feedback),赋予模型反思和自我校验的能力,弥合指令与视觉对齐的鸿沟。成熟度感知的协同进化强化学习 (Maturity-Aware Co-evolutionary RL): 设计了一套基于GRPO的解耦奖励机制。通过“成熟度”指标动态调整探索(Diversity)与利用(Accuracy)的权重,使得Proposer与Critic作为共生Agent共同进化,避免了RL训练中常见的模式坍塌(Mode Collapse)。SOTA性能: 在 MMBench-GUI、ScreenSpot-Pro、OSWorld-G 等6个主流基准测试上实现全面领先(相对提升高达17.2%),不仅显著提升了Top-1准确率,还以更少的Token开销击败了各类基于Test-time scaling的几何聚合策略。
3. 具体案例剖析 (Case Study)
为了直观理解 Propose-then-Critic 的运作机制,以下是一个基于 Blender 3D 软件的复杂测试用例:
指令 (Instruction): "Enter Sculpt mode to use Inflate brush to enlarge some specific areas."(进入雕刻模式使用膨胀笔刷放大特定区域)
Step 1: Proposer (Candidate Generation) 5个离散坐标点 。
Step 2: Visualization Bridge
Step 3: Critic (Point Discrimination)
分析结果: 通过此机制,Proposer利用空间多样性进行了有效的“撒网”(Hedge bets),而Critic通过直观的视觉反馈排除了由于回归方差导致的“合理但不精确”的干扰项,实现了100%的精准定位。
4. 方法论与技术实现 (Methodology)
框架命名为 COPC (Co-evolutionary framework of Proposer and Visual Critic) ,构建于 GRPO (Grouped Reward Policy Optimization) 之上,由三个核心模块构成:
4.1 Propose-then-Critic 统一范式
生成阶段 (The Proposer): $\mathcal{P} \sim \pi_\theta(\cdot|\mathcal{I}, \mathcal{T}, \text{prompt}_{gen})$。输入原始图像 $\mathcal{I}$ 和指令 $\mathcal{T}$,模型单次生成 $K$ 个候选坐标集合 $\mathcal{P}$。渲染桥接 (Visualization): $\mathcal{I}_{vis} = \mathcal{V}(\mathcal{I}, \mathcal{P})$。在截图上将候选点以带数字标签的Marker进行渲染。判别阶段 (The Critic): $\rho \sim \pi_\theta(\cdot|H_{gen}, \mathcal{I}_{vis}, \text{prompt}_{crit})$。模型基于包含候选标记的图像 $\mathcal{I}_{vis}$ 和前文历史,输出针对所有标记点的排序序列 $\rho$。最终采纳 Top-1 结果。
4.2 解耦奖励设计 (Decoupled Reward Construction)
为防止在RL优化中Proposer和Critic相互掣肘,作者对两者设计了完全独立的 Reward:
Proposer 奖励:
准确性奖励 ($R_{acc}$): 使用高斯核映射坐标到GT的距离,并通过Softmax聚合,外加二元命中奖励。Softmax确保优先奖励最佳候选,避免平均主义打压探索意愿:
$$ R_{acc} = \sum_{i=1}^K \text{Softmax}(s_i) \cdot s_i + \frac{1}{K} \sum_{i=1}^K r_{hit,i} $$覆盖率/多样性奖励 ($R_{cov}$): 计算坐标集合协方差矩阵 $\Sigma$ 的行列式(代表多边形面积体积),映射至 $[0,1]$ 防止发散。确保Proposer不会陷入生成 K 个完全重叠坐标的 Mode Collapse。
$$ R_{cov} = \tanh \left( \sqrt{|\det(\Sigma)|} + \epsilon \right) $$
Critic 奖励:
Top-1选择奖励 ($R_{top1}$): 严格对齐最终推理目标,仅当排在首位的点质量高时给予奖励。排名质量奖励 ($R_{ndcg}$): 使用 NDCG (Normalized Discounted Cumulative Gain) 评估。对靠前的排序错误施加重罚,促使 Critic 能够区分目标与高难度干扰项(Hard Negatives)。
4.3 成熟度感知的协同进化 (Maturity-Aware Co-Evolution)
直接将所有Reward相加会导致冷启动失败(例如模型还没学会定位,就开始为了多样性奖励而在屏幕上乱跑)。COPC 引入了基于指数移动平均(EMA)的成熟度指标:Proposer的成熟度 $C_P$ 和 Critic的成熟度 $C_J$。
最终动态权重:$R_{Proposer} = R_{acc} + C_J \cdot R_{cov}$, $R_{Critic} = R_{top1} + C_P \cdot R_{ndcg}$
互锁进化飞轮: 训练初期主要学习 $R_{acc}$ 和 $R_{top1}$(学会基础定位)。随着 Proposer 成熟,它生成的坐标会密集地聚集在各种UI元素附近形成 Hard Negatives,倒逼 Critic 提升细粒度视觉鉴别力($R_{ndcg}$);当 Critic 成熟后,它变为了一个高度可靠的“安全网”,允许 Proposer 解锁空间覆盖探索($R_{cov}$),实现“大范围撒网,精准收网”。
5. 实验设置与结论分析 (Experiments & Results)
实验配置: 基于多种设备及平台(如 Widget Caption, OmniAct, OS-ATLAS 等)的数据联合训练。基座模型采用 Qwen2.5-VL(3B/7B)及 Qwen3-VL(2B/4B/8B)系列。
关键结论:
绝对性能领先: 在 OSWorld-G 测试中,基于 UI-Tars1.5 初始化的 COPC 达到 48.5% 准确率。Ours (Qwen3-VL-8B) 更是大幅碾压 GPT-4o、Claude 3.7 Sonnet 及各种开源专用 Agent。SFT 的局限性被验证: 单纯对两阶段推理做 SFT(Two-Stage SFT)虽然提高了 Ora@5(召回率),但 Top-1 的断层下降(高达 19.6% 的 $\Delta$ gap)证明了 SFT 无法教会模型“视觉鉴别(Self-critic)”能力 。而 COPC 能将这种性能流失降到最低(差距缩小到近乎 0)。全面超越 Test-time 几何聚合: 相比于算术平均 (Mean)、坐标中位数 (Coord)、几何中位数 (Geo) 等后处理方式,COPC 依靠显式的视觉鉴别,使得 Top-1 显著优于传统多模态大模型的盲目聚类(解决了落入两个Icon之间无效区域的痛点)。
6. 关键技术亮点分析 (Takeaways for LLM Practitioners)
巧妙的 Token 经济学: 传统 Self-Consistency 需要完整推理 $K$ 次,而 COPC 的 Proposer 通过 System Prompt 在**单次**前向传播中一次性输出包含 $K$ 个坐标的数组,极大地降低了 Inference Latency 和 Token 开销,具有极强的工程落地价值。将不可微分的坐标转换为可直接感知的 Visual Token: 通过在图片上叠加 marker,将一个纯粹的“回归评价问题”转换为 VLM 最擅长的“多模态看图说话排序问题”,这是降低复杂度的神来之笔。Maturity-Aware Curriculum 解决 RL 优化冲突: 在多目标的 RLHF/GRPO 调优中,探索(Diversity/Coverage)与利用(Accuracy)的冲突极度容易导致 Policy 退化。本文基于互相评估维度的 EMA 动态调度权重,构筑了类似于生成对抗网络(GAN)中 Generator 与 Discriminator 螺旋上升的完美闭环,为后续 Agent 的 Test-time RL 训练提供了极佳的借鉴范式。
GeoMind: An Agentic Workflow for Lithology Classification with Reasoned Tool Invocation
中文标题: GeoMind:具有推理工具调用的岩性分类智能体工作流
作者机构: Yitong Zhou, Mingyue Cheng 等(中国科学技术大学,认知智能全国重点实验室)
📄 查看 ArXiv 原文
🔬 研究背景与核心痛点
测井数据(Well Logs)的岩性分类是地质数据挖掘的一项核心序列标注(Sequence Labeling)任务。在这个场景中,我们需要将一维深度轴上、多通道、带有强噪的物理测量信号(如伽马射线、电阻率、声波时差)映射为离散的岩性标签(如页岩、砂岩、灰岩)。目前的痛点主要集中在以下两个互补方向上的缺陷:
传统数值驱动模型(如XGBoost, LSTMFCN)的脆弱性: 这类模型高度依赖数据统计学关联,在遇到测井仪器响应波动或地层边界模糊时,极易过拟合局部“椒盐噪声(salt-and-pepper noise)”,导致预测结果出现剧烈震荡,违背地层学先验(如出现物理上不可能存在的数厘米厚度的岩层交替)。主流大语言模型(LLM)的数值迟钝性: 尽管近期出现了 MOMENT, GPT4TS 等面向时序数据的基础模型,但在处理纯粹的多通道微小数值浮动时缺乏精确感知。且传统的单步判别式(Single-step discriminative mapping)预测范式剥夺了模型进行多次收集证据、交叉验证和运用专业地质约束来进行“自我修正(Self-correction)”的机会,这与人类地质专家反复比对图谱、查阅地质规则的分析行为相去甚远。
💡 核心贡献
针对上述“数值精准性”与“语义连贯性”难以兼得的痛点,研究团队提出了一个名为 GeoMind 的 Tool-augmented Agentic 框架。其核心创新在于:
Agentic 专家级工作流: 摒弃了单步预测,将岩性分类建模为一个包含 Planner(规划者)、Executor(执行者)、Reflector(反思者) 的多步推理序列。赋予 LLM 调用外部感知、推理与逻辑校验工具的能力。引入多粒度过程监督(Process-Supervised Training): 摆脱了传统 Agent 强化学习仅依靠最终结果(Outcome-only)带来的稀疏奖励问题,设计了基于模块的细粒度过程奖励。提出 MA-GRPO 强化学习优化策略: 首创 Module-Aware GRPO(模块感知组相对策略优化) ,不仅解决了复杂长链 Agentic Workflow 中的信用分配(Credit Assignment)难题,还有效降低了显存消耗并加速了强化学习的收敛。
🔍 具体案例剖析 (Case Study)
我们可以通过 GeoMind 中 Reflector(反思者) 模块在真实测井判定中的一个经典案例(Conflict Arbitrage),来理解 Agent 是如何进行多源证据融合推理的:
输入(多源证据冲突): 在某段深度窗口内,三个异构分析工具给出了不同意见:
Neural Net(神经网络预测器): 基于局部高维特征,预测结果为 [Shale (页岩)] (置信度高,但可能是局部噪点引起)。Neighbors(基于KNN历史井段检索): 检索最相似层段后给出的历史投票为 [Sandstone (砂岩)] 。Context Trend(语义趋势解译器): 将曲线平移转为文本后,发现该深度段具有明显的“向上变细(upward-fining)”特征,推测为 [Sandstone (砂岩)] 。
Reflector 的思考路径与最终输出: "Detected conflict at boundary... The neural predictor leans towards Shale, but the contextual trend pattern (stable low Gamma Ray turning into a sharp increase) combined with strong neighbor similarity suggests a sandy layer before the boundary transition. Final Output: [Sandstone] "
⚙️ 方法论与技术实现
1. Agentic 工作流 (Planner-Executor-Reflector)
GeoMind 以 Qwen3-4B 为底座大模型,解耦成三大协同模块:
Planner(规划者): 接收输入窗口 $X_{t:t+k-1}$,分析信号波动性并生成执行计划序列 $\mathcal{P}_t = (a_{t,1}, a_{t,2}, ...)$,即动态决定调用哪些分析工具。Executor(执行者): 利用三层工具箱获取中间证据:
Perception Tools :将一维多通道数组转换为自然语言趋势(Trend Narrative),以及检索历史相似窗口。Reasoning Tools :整合邻居投票置信度(Neighbor Vote)、轻量级数值网络预测概率(Neural Prob),由语义推理引擎输出初步判断。Analysis Tools :运行共识冲突扫描器(Conflict Scanner),并使用基于训练集标签学习的马尔可夫模型进行地层学序列校验(Stratigraphic Sequence Validator)。
Reflector(反思者): 利用函数 $\hat{y}_t, \hat{h}_t = \text{Reflect}(\text{Candidates}, \text{Confidences}, \text{Diagnostics})$ 对冲突进行仲裁并输出包含逻辑 rationale 的结果。
2. 包含模块感知的强化学习 (MA-GRPO)
这是该论文在 Agent 微调层面最核心的技术亮点。标准的 GRPO / PPO 若直接应用于长链工具调用,会导致信用分配(Credit Assignment)极度模糊——系统无法区分最后的失败是因为 Planner 选错了工具,还是 Reflector 判断失误。为此,GeoMind 引入了细粒度 过程奖励(Process Reward) 结合 MA-GRPO :
对于轨迹 $g$ 中的某一个模块 $m$,不再使用贯穿整条轨迹的全局 Return,而是计算当前模块特定的 Advantage $A_m^{(g)}$:
$$A_m^{(g)} = \frac{r_m^{(g)} - \mu_m}{\sigma_m + \epsilon}$$
其优化目标被解耦为模块级代理目标的总和:
$$\mathcal{J}_{\text{MA-GRPO}}(\theta) = \sum_{m \in \mathcal{M}} \mathbb{E}_{q \sim \mathcal{D}_m} \left[ \frac{1}{G} \sum_{g=1}^{G} \left( \rho_m^{(g)}(\theta) A_m^{(g)} \right) - \beta \mathbb{D}_{\text{KL}}\left( \pi_\theta(\cdot|q_m) \parallel \pi_{\text{ref}}(\cdot|q_m) \right) \right]$$
三种过程奖励包含:(1) Trend Quality Reward(基于GPT-5充当裁判判定的趋势捕捉质量);(2) LLM Accuracy Reward(推理中间态是否命中Ground Truth);(3) Reflection Correction Reward(Reflector在多模型意见分歧时,成功抓取并选择正确标签所获得的激励)。
3. K-Fold Stacking 消除分布偏移 (Distribution Shift)
在复合智能体系统中,如果在同分布数据上联合训练数值预测网络和RL Agent,Agent在训练期会看到高置信度且极度准确的数值网络输出,导致 Policy Collapse(过度依赖数值网络而退化掉验证和修正能力)。GeoMind 采用 “Out-of-Fold (OOF)” 的交叉预测机制为 Agent 生成输入特征,强制 Agent 在具有真实泛化误差的 “不确定性环境” 下学习反思策略。
📊 实验设置与结论分析
模型在四大真实开源地质数据集进行了基准测试(SEAM, Facies, FORCE, GeoLink),评估指标为 Weighted F1。核心实验结论如下:
一致领先的性能: GeoMind 显著超过了基于深度时间序列的模型(如 InceptionTime, LSTMFCN)和时序预训练大模型(MOMENT, GPT4TS)。这证明跨模态证据融合远比单调地堆叠序列参数模型更有效。惊人的抗噪能力与低地层破碎率: 为了衡量“椒盐噪声”导致的物理不合理判决,作者定义了 Fragmentation Rate (厚度低于最低有效地层厚度的片段占比)。相较于 XGBoost Baseline,GeoMind 凭借 Stratigraphic Sequence Validator,将 Facies 数据集的地层破碎率相对降低了 27.9% ,极大提升了结果的现实地质可解释性。即插即用的轻量级增强: 论文证明,无论是把底层数值分类器替换为 XGBoost、InceptionTime 还是 GPT4TS,套上 GeoMind 这套 Agent Workflow 外壳后,均能取得 +3.7% ~ +4.8% 的 F1 稳定涨幅。
🌟 关键技术亮点分析 (Takeaways)
从资深大模型开发者的视角来看,这篇工作非常有启发性,特别是在 Agent 系统在复杂业务落地时的训练范式 上:
MA-GRPO 对显存墙的巧妙规避: 标准 GRPO 要求保存整个长链 Trajectory (Planner $\rightarrow$ Executor $\rightarrow$ Reflector) 的计算图以供 Reward 在结尾反向传播。而 MA-GRPO 将梯度累加局部化。如论文附录指出:$\nabla_\theta \mathcal{J}_{\text{Total}} = \nabla_\theta \mathcal{J}_{\text{Trend}} + \nabla_\theta \mathcal{J}_{\text{Reasoning}} + \dots$ 只要算完 Module $m$ 局部的 Advantage,累加梯度后,立刻释放该部分的激活缓存(Activation Graph) ,仅保留无梯度的 KV-Cache 供下游参考。这种分解极大地压低了 Peak Memory,使长链的 Agent 端到端强化学习变得真正可扩展。利用 Process Rewards 稳定收敛: 论文展示的训练轨迹图中,采用 MA-GRPO 的 Actor Gradient Norm 显著平滑且收敛极快。这反映出“行为修正”本身就是一个分阶段的工作,依靠结果反推(Outcome reward)带来的噪音极大,给每一个 Tool Call 和 Reflection 提供特定的微观奖励(Process Reward)是打破复杂智能体对齐瓶颈的关键。Domain Prior SFT 与 RL 的配合: 在进入 RL 前,作者利用 Gemini 构造了 600条 QA 以及 200条 对比判定(Contrastive QA) 进行 SFT 注入地学领域基础认知。这种先给 LLM 建立边界概念,再依靠 RL 进行工具调用优化的分层训练体系非常扎实。
🤖 当 Agent 看起来都一样:量化工具使用行为中由蒸馏引起的相似性
When Agents Look the Same: Quantifying Distillation-Induced Similarity in Tool-Use Behaviors
作者: Chenghao Yang, Yuning Zhang, Zhoufutu Wen, Tao Gong, Jiaheng Liu, Qi Chu, Nenghai Yu
机构: 中国科学技术大学 (USTC),安徽省数字安全重点实验室,M-A-P,南京大学 (NJU)
📄 查看 ArXiv 原文
🔍 研究背景与痛点 (Background & Motivation)
在当前 LLM Agent 的“寒武纪大爆发”中,资深从业者常常会产生一种强烈的“既视感(déjà vu)”:尽管各个厂商宣称自家的模型架构和预训练数据各不相同,但许多新兴的 Agent 在处理复杂任务时,表现出了令人惊讶的一致性。它们共享着几乎相同的推理步骤(Reasoning traces)、冗余的工具调用习惯,甚至会在完全相同的地方以同样的方式失败(Failure modes)。这强烈暗示了当前开源或新兴闭源模型生态中,广泛存在对少数处于统治地位的 Teacher Model(如 Claude、GPT-4)的模型蒸馏(Model Distillation) 。
然而,现有的相似度评估指标(如 N-gram, BERTScore, 甚至是基于生成的 RSE)在量化这种“蒸馏导致的同质化”时面临巨大挑战:
无法区分“必需行为”与“非必需行为”: 在工具调用任务中,完成任务有一条“必须”走的主干道(Mandatory behaviors,例如退票必须调用 cancel_ticket)。现有指标会将这些为了任务成功的必选动作计入相似度,从而掩盖了模型真正的“自主偏好”。静态文本视角的局限: 仅比较最终回复或局部交互,无法捕捉 Agent 在多步轨迹(Multi-step Trajectory)中展现出的动态图结构特征(如工具链依赖、错误重试策略)。
为了探究模型到底是“殊途同归(因为任务只有一种最优解)”还是“盲目模仿(连 Teacher 的冗余操作也一并学来)”,本文提出了解耦任务刚性需求与模型自主偏好的评估框架。
💡 核心贡献 (Core Contributions)
首个专注于 Tool-use Agent 蒸馏量化的评估框架: 提出系统性的方法,将 Agent 轨迹中的“强制性任务要求”与“非强制性行为模式(即模型的自由度)”进行了解耦。两大互补的且具高可解释性的相似度指标:
RPS (Response Pattern Similarity): 用于捕捉系统侧/自然语言对齐层面的相似度(话术风格、结构排版、推理对齐)。AGS (Action Graph Similarity): 用于捕捉工具侧/动作图谱层面的相似度(非必选工具的偏好、调用顺序习惯、数据依赖复用)。
大规模生态测绘与实证发现: 评估了来自 8 个厂商的 18 个主流模型在 $\tau$-Bench 及其变体上的表现,揭示了当前生态中显著的行为同质化现象。例如,研究发现 Kimi-K2 (thinking) 在行为模式上与 Claude Sonnet 4.5 高度一致,甚至超过了 Anthropic 自家 Opus 模型与 Sonnet 的相似度。
⚙️ 方法论与技术实现 (Methodology)
给定轨迹 $\tau$,模型输出包含:(i) 回复, (ii) 工具调用, (iii) 工具执行结果。框架包含两个正交维度的度量:
1. 响应模式相似度 RPS (Response Pattern Similarity)
由于不同模型完成任务的步数不一,直接计算文本相似度会因为不对齐而失效。RPS 设计了基于语义对齐的两阶段流水线:
阶段切分 (Stage Annotation): 利用 LLM 将长轨迹中的每个回合标注为五种规范化意图阶段之一:Authentication(身份验证)、Elicitation(信息收集)、Execution(执行修改)、Verification(修改前确认)、Notification(结果通知)。相似度打分 (Similarity Scoring): LLM Judge 仅对两个模型共有的阶段 进行 1-5 分的评分,评估维度包括:Style (风格习惯) 、Structure (结构模板) 、Alignment (推理与执行对齐) 。
2. 动作图相似度 AGS (Action Graph Similarity)
将一条执行轨迹映射为动作流图 (Action Flow Graph) $G = (V, E_s, E_d)$,其中 $V$ 为工具调用节点,$E_s$ 为时序边,$E_d$ 为数据依赖边(需通过 LLM 验证非虚假匹配)。AGS 包含三个核心子指标:
非必选工具一致性 ($S_{node}$): 这是最核心的去偏设计。对于任务 $t$,首先计算所有成功模型的工具交集作为必选工具集 $\mathcal{F}_t^{\text{mandatory}} = \bigcap_{M \in \mathcal{M}^*_t} \text{Tools}(M, t)$。从每个模型的工具轨迹中剔除必选工具后,计算它们在非必选工具(Optional tools) 选择上的一致性比例。共享非必选工具是强烈的蒸馏信号。时序习惯相似度 ($S_{seq}$): 将局部执行习惯抽象为一个三维特征向量,包括:写后验证率 (Post-write verification rate)、写前确认率 (Pre-write confirmation rate)、错误重试率 (Error retry rate)。计算模型间该特征向量的余弦相似度。依赖图谱相似度 ($S_{dep}$): 衡量模型是否倾向于构建复杂的长依赖链。特征向量包含:输出重用率 (Output reuse rate)、最长依赖链深度 (Longest dependency chain)、输出扇出率 (Output fan-out rate)。
最终 AGS 为三者的聚合,能精准定位动作结构层面的模仿痕迹。
🔎 具体案例剖析 (Case Studies)
论文通过具体 Case 展示了指标如何有效捕捉深层次的“行为克隆”,而不仅仅是“任务做对了”。
Case 1: 非必选工具冗余调用的“基因遗传” (AGS $S_{node}$ 视角)
任务场景: 航空退换票服务,用户要求更换近期购买的商品/机票。模型表现:
GPT-5: 直接跳过冗余步骤,精准调用 find_user_id_by_name_zip 定位用户并完成任务。这是最高效的路径。Claude Sonnet 4.5 与 Kimi-K2: 两个模型在处理该任务时,都不约而同地先调用了一个与任务最终成功并非强相关的可选工具 find_user_id_by_email。
分析: 这种即使没有必要,也要执行“额外验证”的偏好(Bad Habit),在 AGS 的 $S_{node}$ 中被敏锐捕捉。数据显示,在双模型均成功完成任务的子集中,Kimi-Claude 的 $S_{node}$ 达到 0.661,是 GPT-Claude (0.196) 的 3.4 倍。
Case 2: 幻觉对齐与指导策略 (RPS Alignment 视角)
任务场景: 电信服务中的“无信号”故障排查。模型表现:
GPT-5: 产生了工具幻觉,向用户输出了 Agent 侧的系统指令(例如:Use toggle_airplane_mode to turn Airplane Mode ON),错误地认为用户能调用系统后台接口。Claude Sonnet 4.5 与 Kimi-K2: 两者均准确识别了工具边界,向用户输出了基于物理真实设备的操作指导(例如:“Pull out the tray, make sure the SIM card is seated properly” / “Place the SIM card back”)。
分析: 尽管 Kimi 和 Claude 在表述词汇上有所区别,但它们在“如何将内部推理转化为外部响应”上的对齐模式(Alignment pattern)高度一致,均展现了同级别的安全边界感知和排障策略,RPS 给出了高分。
📊 实验设置与结论分析 (Experiments & Results)
实验在 $\tau$-Bench 及其延伸版上评估了 18 个主流模型,使用 Claude Sonnet 4.5 (thinking) 作为 Reference/Oracle 模型。
控制变量验证(确认指标的有效性): 研究人员使用 Claude 的轨迹通过 LoRA 微调了 Qwen2.5-14B-Instruct。结果显示,微调后模型针对 Teacher (Claude) 的 AGS 从 0.59 提升至 0.72 (+0.13),而针对 Control 模型 (DeepSeek R1) 的 AGS 甚至下降了 (-0.05)。相比之下,传统的图编辑距离 (GED) 在两个方向上都在上升,证明 AGS 具有极强的定向蒸馏检测能力 。“同门模型”的一致性基线: Anthropic 家族内部(Opus 4.1 与 Sonnet 4.5)的 AGS 高达 87.2%,RPS 为 4.18;DeepSeek 家族(R1 与 V3.1)AGS 高达 86.7%。家族内比跨家族平均 AGS 高出 5.9 pp,确立了“高度蒸馏/同源”的阈值基线。惊人的发现:Kimi-K2 (thinking) 的跨家族高度对齐: 在所有非 Anthropic 模型中,Kimi-K2 (thinking) 表现出异乎寻常的相似度。其 AGS 达到 82.7%,RPS 达到 3.65(所有竞品最高)。更为夸张的是,其可选工具一致性 $S_{node}$ 达到 82.6%,依赖图谱相似度 $S_{dep}$ 达到 94.7%,这两项指标甚至超越了 Anthropic 自家 Opus 4.1 与 Sonnet 的相似度 。多参照分析表明,Kimi 与 Claude 的相似度稳定且显著高于与 GPT-5 的相似度。
🌟 关键技术亮点分析 (Technical Highlights)
评测范式从“Performance”向“Behavioral Forensics”转变: 传统的 Benchmark 容易被污染(Data Contamination),只看最终任务成功率掩盖了背后的同质化危机。本文提出从“轨迹特征签名”进行数字取证,为黑盒大模型的溯源提供了全新视角。“去噪”思维在评估中的应用: 设计 $S_{node}$ 时剔除了“Mandatory Tools”,这是全文极为出彩的一笔。如果仅仅比较序列的编辑距离(GED),因为任务目标一致,任何性能好的模型分数都很高。而本文的方法精妙地保留了“模型自主决策的冗余部分”,这才是暴露模型基因的真正位置。生态鲁棒性警示: 论文揭示了一个关键风险:由于大量模型可能蒸馏自少数头部 Teacher,它们不仅继承了能力,也继承了“冗余试错”、“过度推理”等不良习惯。这意味着当前的 Agent 生态可能缺乏真实的对抗鲁棒性——在面对某些 Edge Cases 时,它们可能不再能相互校验,而是会在同一个坑里跌倒。