Learning to Communicate: Toward End-to-End Optimization of Multi-Agent Language Systems
学会交流:迈向多智能体语言系统的端到端优化
作者:Ye Yu, Heming Liu, Haibo Jin, Xiaopeng Yuan, Peng Kuang, Haohan Wang
机构:伊利诺伊大学厄巴纳-香槟分校 (UIUC)
1. 研究背景与痛点 (Background & Pain Points)
基于大语言模型(LLM)的多智能体系统(MAS)在解决复杂推理任务(如数学、编程)方面展现了极大的潜力。其成功归因于两个核心:智能体的角色分配与系统结构,以及智能体间的通信机制(Inter-agent Communication)。然而,当前的 MAS 在通信层面临着显著的瓶颈:
- 离散文本通信的优化壁垒(Discrete Bottleneck):绝大多数 MAS 系统依赖自然语言作为通信接口。由于中间推理状态必须被序列化为离散的 Token 才能传递给下游 Agent,这不仅会丢失细粒度的信息保真度,还在系统层面引入了不可导操作,导致无法在多个 Agent 之间进行端到端的梯度反向传播(Backpropagation)。
- 现有隐式通信方案的局限性:为了突破离散通信的限制,近期有研究尝试通过共享内部表征(如 Hidden States 或 KV Cache)来进行通信。但这些方法要么是无训练的(Training-free,例如强行拼接 KV Cache,容易引发乱码和注意力崩溃),要么仅仅是对齐不同模型的表征(如 C2C),并未将“通信机制”本身作为可学习组件与智能体的推理能力联合优化。
2. 核心贡献 (Core Contributions)
本文提出了一种全新的多智能体训练框架 DiffMAS (Differentiable Multi-Agent System),将基于 KV Cache 的隐式通信作为一种可学习的跨智能体接口进行端到端优化。主要贡献如下:
- 定义了多智能体通信的优化视角:从理论上论证了将通信视为固化接口会阻碍信息的跨智能体传递,并将其转化为一个可联合优化的计算流图。
- 提出 DiffMAS 框架:通过参数高效微调(PEFT/LoRA),将多智能体协作转化为一个端到端可导的训练过程。上游 Agent 将信息编码进 Latent KV Trace,下游 Agent 学习如何解码和利用这些表征,实现通信协议的隐式学习。
- 卓越的性能跃升:在数学推理(AIME)、科学问答(GPQA)、代码生成等任务上,全面超越了单体模型、基于文本的 MAS 以及无训练的隐式 MAS。例如在 Qwen3-8B 上,DiffMAS 在 AIME24 取得了 +26.7% 的准确率提升,GPQA-Diamond 提升 +20.2%。
3. 具体案例剖析 (Case Study: AIME 2024)
为了直观展现 DiffMAS 与无训练隐式通信(LatentMAS)的区别,作者在 AIME24 数据集上提供了一个真实的 Case Study(计算最小球体半径平方的问题)。
输入问题片段:Let $B$ be the set of rectangular boxes with surface area 54 and volume 23. Let $r$ be the radius of the smallest sphere that can contain each of the rectangular boxes... The value of $r^2$ can be written as $p/q$ ... Find $p+q$.
❌ LatentMAS (无训练直接拼接 KV Cache) 的输出:
模型开始尝试计算四面体,胡乱设定边长,逻辑迅速崩溃...
"Okay, let's try to solve this problem step by step... So, we have a tetrahedron ABCD with specific edge lengths. The question is about finding the equal distance from an interior point I to each of the tetrahedron's faces..."
【随后出现乱码和重复模式(Chaotic Decoding)】
"V = sqrt( —CM— / 2 2 2 2 2 2 2 2 2 2 2 2 2 2... query query enjoys eventually enjoys query transformations"
分析:由于预训练 Transformer 没有见过由其他 Agent 强行注入的外部 KV 状态,这种 Distribution Mismatch 破坏了其注意力模式,导致推理想象力漂移和解码崩溃。
✅ DiffMAS (端到端优化的隐式通信) 的输出:
模型清晰地理解了任务,并将上游 Agent 传递的隐式上下文准确解码为解题逻辑...
"Okay, let's try to solve this problem step by step. The question is about finding the square of the radius of the smallest sphere... First, I need to recall that the smallest sphere that can contain a rectangular box would have a diameter equal to the space diagonal of the box. So, the radius $r$ is $\frac{\sqrt{x^2+y^2+z^2}}{2}$..."
【通过一系列稳定的求解步骤】
"...r^2 = 657 / 64. Simplify the Fraction... p = 657 and q = 64, giving p + q = 721. Final Answer: 721 (✓ 正确)"
分析:通过端到端训练,DiffMAS 使得下游 Agent 学会了如何“阅读”上游 Agent 编码在 KV Cache 中的非结构化推理表征,不仅保留了全息信息,还保证了解码阶段极高的稳定性(更低的 Perplexity 波动)。
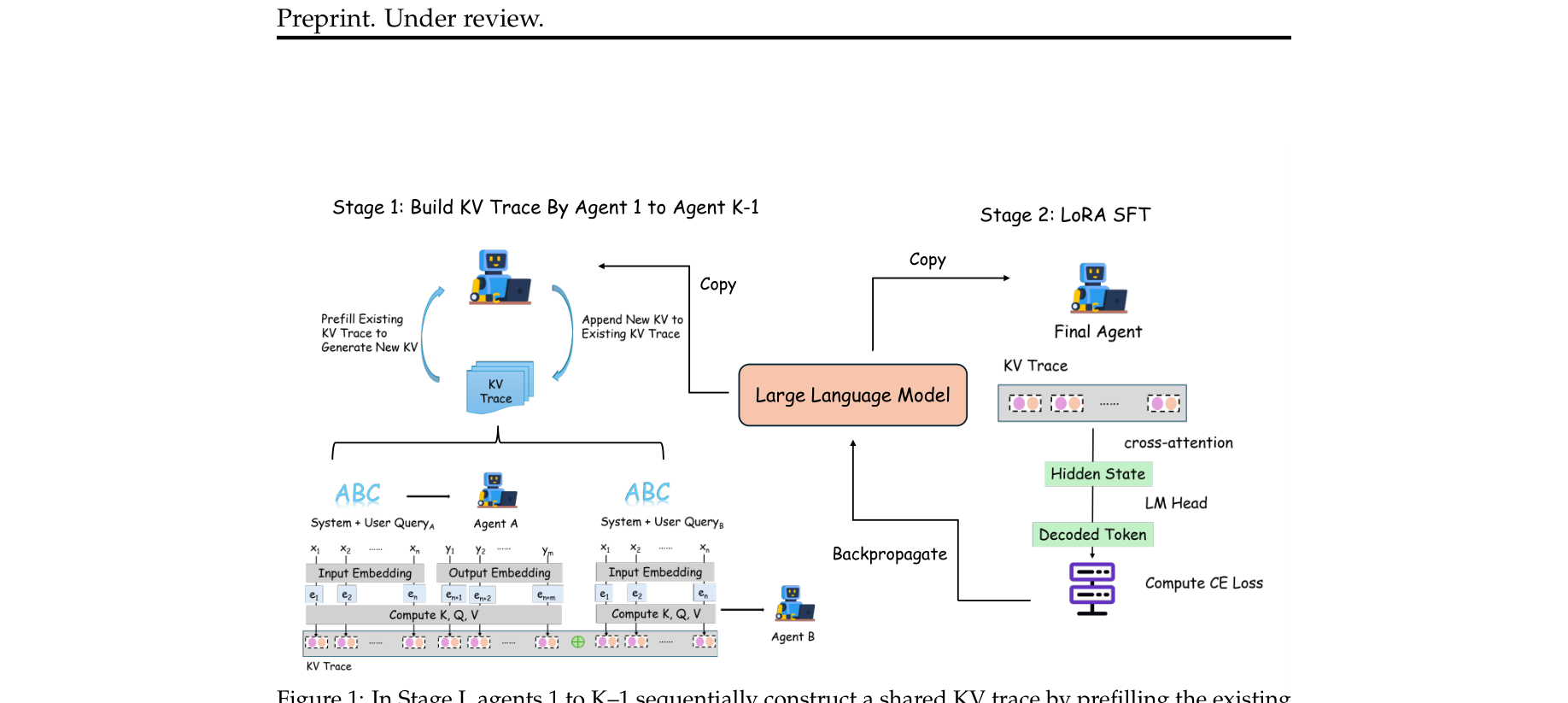
4. 方法论与技术实现 (Methodology)
DiffMAS 的核心理念是将通信机制构建为网络前向计算图中的一段可导路径。系统包含 $K$ 个顺序执行的 Agent(如 Planner, Critic, Refiner, Solver)。
4.1 基于串联的隐式轨迹 (Latent Trace via Concatenation)
通信媒介被定义为一个隐式轨迹序列 $Z$(具体的物理实现为 KV Cache Block)。在第 $j$ 阶段(即第 $j$ 个 Agent 运行时),它会接收前面的全局轨迹 $Z_{1:N_{j-1}}$,并自回归地生成 $T$ 个新的 Latent Block:
$$Z_{1:N_j} = A^{(j)}_\theta(Z_{1:N_{j-1}}; x, p_j)$$
其中 $A^{(j)}_\theta$ 代表当前智能体的计算操作,$x$ 为输入,$p_j$ 是该角色的特定 Prompt。这种方式将整个多智能体交互抽象为一个极深但连贯的可微计算网络。
4.2 训练目标与端到端反向传播 (Training Objective & Backprop)
经过 $K$ 阶段交互后,最后一个 Decoder 输出最终预测分布:
$$p_\theta(y|x, \{p_j\}_{j=1}^K) = \text{Dec}_\theta(x, p_K, Z_{1:N_K})$$
训练采用典型的负对数似然损失 $\mathcal{L}(\theta) = -\log p_\theta(y^\star | \cdot)$。这里最关键的一步是,因为所有中间状态都是连续向量(KV Cache),损失的梯度 $\frac{\partial \mathcal{L}}{\partial Z}$ 能够毫无障碍地跨越 Agent 边界,回传至前置的每一个生成步。 实验中通过共享的预训练 Transformer 配合阶段特定的 LoRA 权重来实现这一过程,仅更新少量参数即可(Parameter-Efficient)。
4.3 为什么必须使用“拼接(Concatenation)”而非“更新(Overwriting)”?
论文在理论部分指出了基于“拼接 KV Cache”架构的重要属性。假设存在一种基于固定大小 Carrier 向量 $h_j$ 不断更新的通信系统(类似传统 RNN 传隐状态),那么梯度反向传播时将遭遇 Jacobian 矩阵的连乘衰减:
$$\left\| \frac{\partial \mathcal{L}}{\partial h_j} \right\|_2 \le \rho^{K-j} \left\| \frac{\partial \mathcal{L}}{\partial h_K} \right\|_2$$
而在 DiffMAS 中,采用的是 KV Cache 追加式拼接(Concatenation):$Z_{1:N_j} = [Z_{1:N_{j-1}}; Z^{(j)}_{1:T}]$。根据微积分链式法则和分块矩阵属性,其关于任意中间阶段 $j$ 输出的偏导满足:
$$\left\| \frac{\partial \mathcal{L}}{\partial Z^{(j)}_{1:T}} \right\|_2 \le \left\| \frac{\partial \mathcal{L}}{\partial Z_{1:N_K}} \right\|_2$$
这从理论上(Proposition 3.1)证明了:基于串联的接口不会引入随网络深度指数衰减的梯度乘数。这使得即使是很早阶段(如 Planner)的 Agent,也能接收到高质量的反馈梯度,从而学会如何正确地为下游编码信息。
5. 实验设置与结论分析 (Experiments & Results)
实验设置:使用了 Qwen3-4B/8B/14B、Ministral3-8B 和 DeepSeek-R1-Distill-Qwen-32B 多种规模模型。任务涵盖 AIME24/25, GPQA-Diamond, HumanEval+, MBPP+ 等重推理测试。训练数据使用了极小规模的高质量 Trace(例如数学仅用 210 条 Hendrycks Math 样本,代码仅用 50 条 HumanEval 样本),侧重测试“极少量数据是否足以学会通信协议”。
5.1 核心表现 (Main Results)
- 极强的涌现能力提升:Qwen3-8B 基础下,DiffMAS 将 AIME24 的零样本准确率从单体的 50.0% 暴涨至 76.7%;GPQA-Diamond 同样从 39.9% 提升至 60.1%。
- 随规模扩展 (Scaling):在 32B 规模的强推理模型 DeepSeek-R1-Distill 上,DiffMAS 依然能在 HumanEval+ 取得 88.5% 的 SOTA 级别性能。
5.2 深入分析:解码稳定性与自我一致性
- Token 级不确定性降低:对推理阶段顶层 25 个 Token 的预测熵(Predictive Entropy)分析表明,相比 LatentMAS 频繁出现的熵尖峰(代表推理不确定和困惑),DiffMAS 的熵增长平滑得多。梯度耦合让上游有效适应并削弱了下游的不确定性。
- 自洽性 (Self-Consistency) 极强:对 AIME 题目进行多次采样发现,DiffMAS 通常要么全对要么全错,呈现极高的内部推理一致性。而 TextMAS 则受限于信息截断,表现出高度极化;LatentMAS 更是极为脆弱。
6. 关键技术亮点分析 (Key Highlights)
对于 LLM/AI Agent 从业者而言,这篇论文带来的重要启示在于:
- 打破离散文本通信的神话:尽管人类可读的 Prompt/Response 对 Debug 很友好,但在追求极致推理性能时,“将高维隐状态强制坍缩为离散 Token” 必然导致严重的信息损耗(Information Compression)。
- 多智能体系统范式转移:从堆砌外壳工程(Prompt Engineering + 路由编排)走向系统级微调(System-level SFT)。DiffMAS 证明了只要打通梯度流,即使只用 50 到 200 条高质量的推理 Trace 进行训练,模型就能迅速学会一套 私有高维通信协议 (Task-aligned Latent Protocol)。
- 通信架构的工程细节:直接拼接 KV Cache 在无微调状态下注定失败(注意力模式会被破坏),但结合 PEFT(如文中使用的 LoRA),模型能快速调整注意力的 Read/Write 机制,使得隐式通信的潜力真正被释放出来,兼顾了表征的丰富性(Expressivity)与生成稳定性(Stability)。