SmartSearch: Process Reward-Guided Query Refinement for Search Agents
SmartSearch:过程奖励引导的搜索智能体查询优化框架
作者:Tongyu Wen, Guanting Dong, Zhicheng Dou
机构:中国人民大学 (Renmin University of China)
🔍 研究背景与核心痛点
在处理知识密集型任务时,基于大语言模型(LLMs)的搜索智能体(Search Agents)展现出了强大的潜力,它们能够通过自主、迭代地调用外部搜索工具来解决静态RAG无法处理的复杂深度探索问题。目前业界对于Agentic RAG的优化(如SFT、RLHF、Prompt Engineering)主要聚焦于推理范式(Reasoning Paradigms)的提升,但往往忽视了一个极其关键的环节:中间搜索查询(Intermediate Search Queries)的质量。
痛点分析:
- 查询模糊引发蝴蝶效应: 智能体在推理中生成的中间Query经常缺乏精确性(例如漏掉关键实体或限定词)。低质量的Query会导致检索出偏离预期甚至充满噪音的文档。
- 误差累积导致最终失败: 错误的信息输入到Agent的Context中,容易引发模型幻觉,使后续推理路径完全偏离(Derail the entire trajectory),极大地限制了搜索智能体的有效性和准确率。
- 基于结果的奖励过于稀疏: 在强化学习(RL)训练中,仅依靠最终答案正确与否(Outcome Reward)提供监督信号,无法对多轮检索中的每一步Query质量进行惩罚或纠正,导致策略优化极不稳定。
💡 核心贡献
本文开创性地将优化重心转移至中间搜索查询的质量上,提出了一套名为 SmartSearch 的综合框架。其核心贡献包括:
- 引入过程奖励机制(Process Rewards): 提出了“双层信用评估(Dual-Level Credit Assessment)”方法,通过规则和轻量级模型对每步Query的“新颖性”和“有用性”进行细粒度打分并生成文本反馈。
- 设计查询重写与优化机制(Query Refinement): 在探索/训练过程中,一旦检测到低质量Query,即利用过程奖励提供的反馈信息触发查询修正,并基于修正后的Query重新生成后续轨迹。
- 面向查询的三阶段课程学习(Curriculum Learning): 构建了一条从 SFT(筛选的高质量轨迹模仿学习) 到 DPO(基于生成的修正数据进行偏好对齐) 再到 GRPO(整合过程奖励的策略强化学习) 的完整训练管线,使Agent逐步内化提升Query质量的能力。
🌰 具体案例剖析 (Case Study)
以 ASearcher 数据集中的一个多跳问题为例,观察低质量Query如何导致失败,以及SmartSearch如何纠正它:
用户提问: "An Annapolis Story" 这部电影由哪位出生于1914年2月15日的美国舞台剧、电影和电视演员主演?
❌ Baseline (存在缺陷的搜索轨迹):
[Thought]: 我查到主演是 Kevin McCarthy。下一步我需要确认他的生日是否是 1914-02-15。
[Search Query]: birthdate of Kevin McCarthy (低质量Query:未加限定词)
[Result]: 检索到的是加州政治家 Kevin McCarthy(生于1965年1月26日)。
[Conclusion]: 生日不匹配,答案未找到 (Not Found)。
✅ SmartSearch干预与修正:
[Process Reward 检测]: 判定该步评分为 0。反馈原因:“检索意图是合理的,但结果没有包含演员 Kevin McCarthy 的生日,而是包含了政治家的信息。”
[Query Refinement 修正]: 模型接收到反馈,将Query修改为 Actor Kevin McCarthy birth date (高质量Query)
[Regenerated Result]: 检索到演员 Kevin McCarthy(1914年2月15日 – 2010年9月11日)。
[Final Answer]: Kevin McCarthy (回答正确)。
⚙️ 方法论与技术实现
1. 过程奖励机制:双层信用评估 (Dual-Level Credit Assessment)
为了判断一个中间Query的好坏,模型从三个维度评估:查询新颖性、意图必要性、检索相关性。
- (1) 基于规则的评估(Query Novelty): 防止Agent反复用不同的Query查出相同的文档。定义新颖性得分 $\mathcal{S}_t^{\text{novel}}$:当当前召回文档与历史文档重合度 $O_t^i$ 大于阈值 $K$ 时,判定冗余。
- (2) 基于模型的评估(Usefulness Check): 采用一个轻量级SFT模型评估意图是否有必要,以及召回结果是否包含能推动问题解答的信息。模型输出打分 $\mathcal{S}_t^{\text{useful}}$ 与具体文本解释 $\mathcal{T}_t^{\text{useful}}$:
$$\mathcal{S}_t^{\text{useful}}, \mathcal{T}_t^{\text{useful}} = \text{LLM}_{\text{eval}}(q, a, H_t)$$
最终得分为两者的逻辑与:$\mathcal{S}_t = 1 \text{ if } (\mathcal{S}_t^{\text{novel}} = 1 \land \mathcal{S}_t^{\text{useful}} = 1) \text{ else } 0$。同时拼接文本解释用于指导下一步。
2. 过程奖励引导的查询重写 (Query Refinement)
对于评分为 0 的低质量Query,利用同一个轻量级LLM,根据上下文和反馈解释进行重写:
$$q_t' = \text{LLM}_{\text{refine}}(q, H_t, \mathcal{T}_t)$$
随后,Agent 会丢弃旧节点,基于新 Query $q_t'$ 继续生成后续轨迹 $H_t'$。这不仅能修复错误轨迹,还是构建高质量训练数据的引擎。
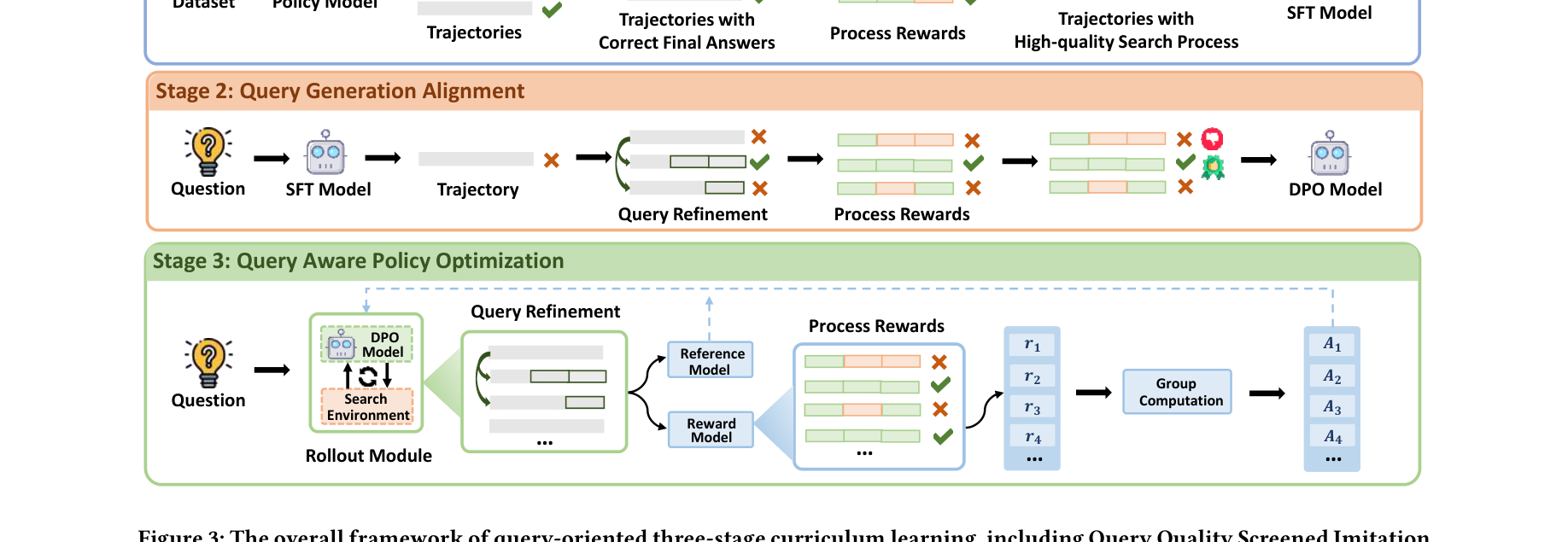
3. 三阶段课程学习 (Three-Stage Curriculum Learning)
Stage-1: 筛选式模仿学习 (Query Quality Screened SFT)
传统的SFT只要最终答案正确即可,但作者发现很多能得到正确答案的轨迹中,中间查询质量依然很差。因此,作者叠加了基于过程奖励的硬过滤,只保留所有步骤 $\mathcal{S}_t=1$ 且结果正确的完美轨迹进行监督微调。
Stage-2: 查询生成对齐 (Query Generation Alignment - DPO)
利用上文提到的Query Refinement机制,模型自动生成一对轨迹(重写前 vs 重写后)。偏好标注规则综合考量:(1) 答案正确者优先;(2) 答案都正确时,低质量查询次数少者优先;(3) 都错误时,高质量查询多者优先。通过DPO促使模型自主避开低效Query。
Stage-3: 查询感知策略优化 (Query Aware Policy Optimization - GRPO)
采用Agentic RL(在此具体使用了DeepSeek数学模型常用的 GRPO 算法)。在Rollout阶段,允许Agent调用Refinement生成多条轨迹。奖励函数设计为结果奖励与过程奖励的结合:
$$r = r_{\text{composite}} + \lambda \cdot r_{\text{format}}$$
其中过程奖励的设计会动态地惩罚轨迹中低质量节点数($n_{\text{wrong}}$)并奖励高质量节点数($n_{\text{correct}}$)。这促使模型不仅“蒙对”答案,更要“搜得准”。
📊 实验设置与结论分析
- 评测基准: 包含4个知识密集型问答数据集 (2WikiMQA, HotpotQA, Bamboogle, Musique) 以及2个开放网络探索任务 (GAIA, WebWalker)。
- 实现细节: 基础策略模型采用 Qwen2.5-3B-Instruct,利用DeepSpeed ZeRO-3与FlashAttention 2进行训练。用于过程奖励与重写的评判/教师模型主要由蒸馏后的 Qwen2.5-3B 承担(标签由Qwen3-32B生成以节约计算开销)。
- 性能表现: 在本地知识库搜索上,SmartSearch以绝对优势(平均 Exact Match 达 37.5%,平均 F1 达 47.2%)击败了单纯依靠Outcome Reward的模型(如 Search-R1)以及先前的过程奖励模型(如 StepSearch)。
- 泛化能力: 尽管模型仅在Wikipedia-based本地搜索数据上进行了训练,但其在Web Search(如GAIA)的开放评测中同样表现出极强的zero-shot泛化能力。
- 搜索效率提升: 消融实验证明,随着低质量Query的减少,模型无效搜索调用的次数显著下降(搜索效率曲线显著优于 Baseline)。这证明优化中间Query不仅提升了天花板,还降低了推理Token消耗。
🌟 资深从业者技术看点分析
- RAG的范式转移:从“如何推理”到“如何发问”。 很多企业在做Agentic RAG时,过度关注给LLM做复杂的Re-Ranker或注入极其复杂的规划Prompt,却忽略了如果搜索工具的输入(Query)本身就是一坨屎,无论后端多强大也救不回来。这篇论文通过一套完整的流程把对Query的关注给规范化和自动化了。
- PRM(过程奖励模型)落地的工程智慧。 在多轮搜索这种长轨迹任务中,如果用大模型做PRM,推理成本极高;如果纯基于规则,又无法泛化。作者采用 Rule-based(新颖度检测) + 轻量化LLM(相关度评估,Teacher-Student 范式蒸馏) 的双层设计,是实际业务中非常值得借鉴的性价比打法(有效性-效率折中)。
- 将Refinement作为Rollout策略的新思路。 在标准的 RLHF(如 PPO/GRPO)中,Rollout 往往依赖随机采样或温度调节,非常盲目。SmartSearch 创新性地在探索阶段直接把错误节点利用 Refine 模型修补过来再生成,不仅能保证生成的Trajectory多样性,还大大提高了遇到高回报状态的概率,加速了RL的收敛。