超越随机探索:什么让训练数据在智能体搜索中更有价值?
英文标题:Beyond Stochastic Exploration: What Makes Training Data Valuable for Agentic Search
作者:Chuzhan Hao, Wenfeng Feng, Guochao Jiang, Guofeng Quan, Guohua Liu, Yuewei Zhang
机构:Alibaba Cloud
📄 查看 ArXiv 原文
研究背景与痛点
这篇论文切中的核心问题是:Search Agent 的 RL 训练往往高度依赖 outcome reward 驱动的随机探索,但多跳搜索与工具调用场景的 credit assignment 极差,导致大量 rollout 轨迹质量低、方差大、训练不稳定。
作者认为,真正有价值的不是“更多随机探索”,而是把历史探索中已经暴露出来的成功经验与失败教训结构化沉淀下来,让后续训练从“瞎试”转成“有经验的探索”。
核心贡献
- 提出 HiExp (Hierarchical Experience),把经验划分为实例级、模式级、策略级三层。
- 利用成功/失败轨迹的对比反思自动抽取经验,不依赖人工规则或外部知识工程。
- 在 RL rollout 中按需检索经验进行 experience-aligned training,显著降低探索噪声。
- 在 multi-hop QA 与数学推理任务上对小中型模型带来明显增益。
具体案例剖析
论文给出的典型多约束案例是:先找某位诗人,再找同年获奖剧作家,再定位某年某月创作的戏剧名称。若没有经验指导,模型很容易从错误的时间约束或错误的人物实体开始搜索。
输入范式:“某位在 2016 年 5 月创作作品的剧作家,与某位诗人同年获得 MacArthur Fellowship,该作品叫什么?”
HiExp 的作用:
- 模式级经验先要求模型按“诗人 → 获奖年份 → 剧作家 → 作品时间”的顺序拆解。
- 实例级经验再提醒模型区分“作品首演日期”和“实际写作日期”。
最终模型能稳定收敛到正确作品,而不是陷入大范围关键词搜索。
方法论与技术实现
系统分为离线经验构建和在线经验对齐两部分。
离线阶段,对同一问题的成功与失败轨迹做反思提炼:
$$e_i, d_i = \mathrm{Reflect}(x_i, y_i^+, y_i^-)$$
然后对经验摘要做聚类,形成从具体到抽象的层级知识。
在线阶段,在中间查询 $q_t$ 生成后,从经验库中检索最相关经验:
$$e^* = \arg\max_{e \in \mathrm{HEK}} \mathrm{cos\_sim}(\phi(q_t), \phi(d_e))$$
为了防止模型机械复制检索经验,训练时会对经验文本进行 masking,这一点很像“外挂经验但不允许抄答案”的设计。
实验设置与结论分析
论文在 HotpotQA、2Wiki、Musique、Bamboogle 以及 AIME、MATH500 等任务上做了广泛实验。
- 在 multi-hop QA 上,HiExp 相比 vanilla RL 搜索智能体明显更稳、更强。
- 在数学推理上也有效,说明其本质不是“搜索特化 trick”,而是更普适的经验对齐框架。
- 模式级经验与实例级经验组合效果最好,说明抽象策略和局部纠偏必须同时存在。
关键技术亮点分析
- 把 RAG 从“检索事实”推进到“检索策略经验”,非常有启发性。
- 它本质上在做 agent RL 的 variance reduction。
- 对于 Deep Research / Search Agent 团队,这是一套很值得复用的数据飞轮方法。
Probe-then-Plan:面向工业电商搜索的环境感知规划
英文标题:Probe-then-Plan: Environment-Aware Planning for Industrial E-commerce Search
作者:Mengxiang Chen, Zhouwei Zhai, Jin Li
机构:JD.com
📄 查看 ArXiv 原文
研究背景与痛点
工业电商搜索与开放域搜索不同,它高度依赖底层检索环境的真实反馈,比如库存、商品属性分布、检索器能力边界和业务目标。传统 query rewrite 只会“猜环境”,很容易生成系统并不支持的计划;而完整的 multi-step ReAct agent 又过于昂贵和缓慢。
作者把这一矛盾概括为 blindness-latency dilemma:不看环境就盲,深看环境又慢。
核心贡献
- 提出 Probe-then-Plan:先用轻量检索探针拿到环境快照,再生成 grounded search plan。
- 用 teacher LLM 离线合成高质量计划数据,再对小模型 planner 做 SFT + GRPO。
- 设计 complexity-aware router,确保只有复杂 query 才触发规划链路。
- 在京东真实线上流量中验证了业务收益。
具体案例剖析
Case 1:“bottoms match green shirt”
如果不感知环境,模型会继续围绕 green shirt 做 rewrite,结果检索出来仍是衬衫。Probe 先看一眼初始检索结果,判断这是 precision failure,于是把搜索空间具象化为下装类别,比如 khakis、jeans。
Case 2:“bird watching camera”
Planner 会把自然语言意图映射到更可执行的技术属性,例如 telephoto camera,而不是直接照搬原始表述。
方法论与技术实现
规划问题被写为条件策略:
$$\mathcal{P} \sim \pi_\theta(\cdot \mid q, O_{init})$$
其中 $O_{init}$ 是 probe 给出的检索环境快照。训练分三阶段:teacher 合成数据、planner 做 SFT + RL、router 控制线上路由。
其业务对齐奖励函数为:
$$R(P_i) = \frac{1}{K} \sum_{d_j \in \mathcal{D}_{P_i}} \mathbb{I}(\phi_{rel}(q,d_j)\ge\tau) \cdot \phi_{cvr}(q,d_j)$$
这里的 hard relevance gate 非常关键,它防止模型为了优化 CVR 而去召回不相关但“更好卖”的商品。
实验设置与结论分析
- 离线评测中明显优于 blind rewriter 和仅 SFT 的 planner。
- 线上 A/B 中能带来显著 UCVR、GMV 提升,且复杂 query 收益更明显。
- 简单 query 走 fast path,复杂 query 才走 planning chain,延迟控制得很好。
关键技术亮点分析
- 这是非常典型的 production-ready LLM system design。
- 单次 probe 替代多轮深度反思,是工业时延约束下非常聪明的折中。
- 把 RL 奖励和业务目标直接绑定,对推荐/搜索团队很有参考价值。
SE-Search:基于记忆与稠密奖励的自我进化搜索智能体
英文标题:SE-Search: Self-Evolving Search Agent via Memory and Dense Reward
作者:Jian Li, Yizhang Jin, Dongqi Liu, Hang Ding, Jiafu Wu, Dongsheng Chen, Yunhang Shen, Yulei Qin, Ying Tai, Chengjie Wang, Xiaotong Yuan, Yabiao Wang
机构:Nanjing University, Tencent YoutuLab
📄 查看 ArXiv 原文
研究背景与痛点
Search Agent 已经超越传统 RAG,但它很快会遇到两个问题:第一,搜索出来的文档太 noisy,直接拼上下文会污染后续推理;第二,仅依赖最终答案对错来做 RL,奖励太稀疏,模型不知道“哪一步搜得好、哪一步搜得差”。
SE-Search 的目标非常明确:一边把搜索结果“提纯成记忆”,一边把 RL 奖励“细化成多维密集反馈”。
核心贡献
- 提出 memory purification,用记忆压缩替代原始文档堆叠。
- 提出 atomic query training,鼓励简短、差异化查询。
- 设计 query、memory、format、outcome 四类 dense rewards。
- 在多跳问答上的收益特别明显,优于 Search-R1 等基线。
具体案例剖析
问题:“Who is the spouse of the actor who played Scarlett in Gone with the Wind?”
SE-Search 不会把两轮搜索得到的大段文档全部塞回上下文,而是先将关键信息压缩成两段记忆:
<memory> Vivien Leigh played Scarlett.</memory><memory> Vivien Leigh is married to Laurence Olivier.</memory>
这样后续推理完全围绕 distilled memory 展开,显著减小上下文噪声。
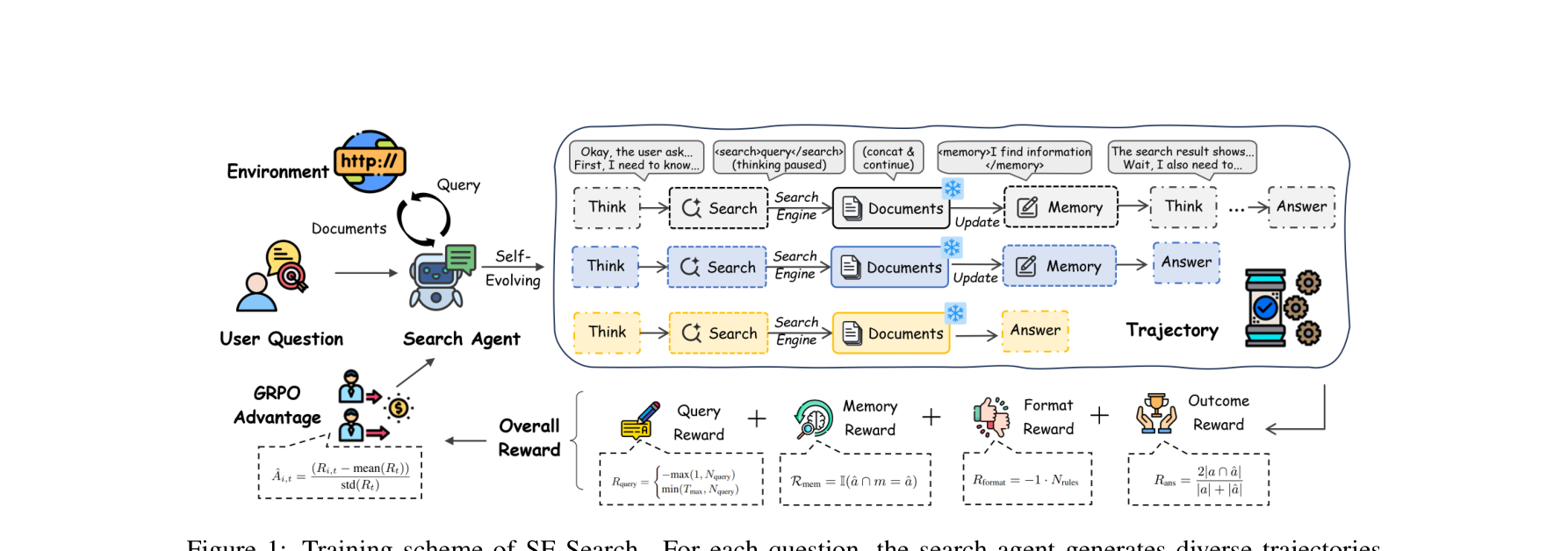 图注:SE-Search 通过 Think/Search/Documents/Memory/Answer 的结构化轨迹,以及四种 dense reward 做 GRPO 优化。
图注:SE-Search 通过 Think/Search/Documents/Memory/Answer 的结构化轨迹,以及四种 dense reward 做 GRPO 优化。
方法论与技术实现
总奖励写为:
$$R_{\mathrm{Dense}} = R_{\mathrm{ans}} + \alpha R_{\mathrm{mem}} + \gamma \mu R_{\mathrm{query}} + \gamma R_{\mathrm{format}}$$
其中:
- Outcome reward: 最终答案质量。
- Memory reward: 记忆是否覆盖关键信息。
- Query reward: 查询是否简短且多样。
- Format reward: 动作 token 与轮次是否规范。
GRPO 通过 group-based advantage 对多条轨迹相对归一化,让“哪些中间行为更有价值”变得可学习。
实验设置与结论分析
- 使用 Qwen2.5 3B/7B/14B 为基础模型。
- 在单跳任务上,搜索次数自然减少;在多跳任务上,搜索次数保持更高,说明模型学会了按任务复杂度自适应分配动作。
- 相对 Search-R1,在多跳 benchmark 上提升尤其明显。
关键技术亮点分析
- memory purification 是对 long-context 噪声问题的直接回应。
- dense reward 才是这篇论文真正的核心资产。
- 对于任何需要“搜索 + 推理 + 工具调用”的 agent,这套 reward 设计都很可迁移。
ShopSimulator:评估与探索用于购物助手的 RL 驱动 LLM Agent
英文标题:ShopSimulator: Evaluating and Exploring RL-Driven LLM Agent for Shopping Assistants
作者:Pei Wang, Yanan Wu, Xiaoshuai Song, Weixun Wang, Gengru Chen, Zhongwen Li, Kezhong Yan, Ken Deng, Qi Liu, Shuaibing Zhao, Shaopan Xiong, Xuepeng Liu, Xuefeng Chen, Wanxi Deng, Wenbo Su, Bo Zheng
机构:Alibaba Group
📄 查看 ArXiv 原文
研究背景与痛点
购物助手不是普通对话 agent。它需要同时理解多轮需求、用户长期偏好、细粒度属性约束、库存变化以及最终购买动作。现有 benchmark 大多只覆盖很窄的一部分能力,而且很少支持 RL 训练闭环。
这篇论文的基本立场是:没有一个足够真实、可交互、可训练的 shopping environment,就无法认真研究 shopping agent。
核心贡献
- 构建大规模中文电商仿真环境 ShopSimulator。
- 支持用户画像、多轮对话、搜索、点击、购买等完整动作空间。
- 系统评估一流 LLM,发现即使强模型在全流程成功率上也远未饱和。
- 验证了 SFT + RL 比单独使用任一种训练方式更有效。
具体案例剖析
用户输入:“我想买一双羽毛球鞋,最好是蓝白配色的,看起来干净些。”
用户画像:偏好 YONEX / ASICS、尺码 40、价格 200-800、偏好缓震和耐磨。
高质量 agent 不应只搜“蓝白 羽毛球鞋”,而应该融合显式短期需求与长期偏好,像这样构造搜索与澄清:
search[YONEX badminton shoes blue white size 40 cushioning wear-resistant]- 若商品候选在宽楦、中性款或价格上有冲突,再向用户追问确认。
这个环境特别强调:任何一个约束漏掉,最终都可能失败。
方法论与技术实现
论文把购物过程建模为 MDP:
$$a_t = \pi_\theta(o_t, u_t, p), \quad o_{t+1}, u_{t+1} = \mathcal{E}(o_t, a_t)$$
其中 $o_t$ 是环境观察,$u_t$ 是当前轮用户表达,$p$ 是长期画像。
作者还设计了两种奖励:
- 宽松奖励: 允许部分约束匹配。
- 严格奖励: 类目、属性、选项、价格都必须过关,任何一个维度掉链子都会被放大惩罚。
严格奖励更符合真实电商 agent 的要求,因为用户买错尺码和买错颜色都不是“部分成功”。
实验设置与结论分析
- 即使是很强的闭源/开源模型,在 full-success 指标上也没有压倒性优势。
- SFT 解决冷启动与基本 workflow,RL 负责把模型往细粒度偏好与长程交互上推得更准。
- 严格奖励训练目标往往优于宽松奖励,因为它能逼模型补齐最脆弱的那块短板。
关键技术亮点分析
- 这是 shopping agent 方向很重要的基础设施论文。
- 它说明 RL 对“偏好对齐 + 长序列交互”真的有独特价值。
- 严格乘法式 reward 对很多真实交易型 agent 场景都很有借鉴意义。
基于强化学习与情境化推理的对话式 Agentic Search
英文标题:Agentic Conversational Search with Contextualized Reasoning via Reinforcement Learning
作者:Fengran Mo, Yifan Gao, Sha Li, Hansi Zeng, Xin Liu, Zhaoxuan Tan, Xian Li, Jianshu Chen, Dakuo Wang, Meng Jiang
机构:Université de Montréal, Amazon, UMass Amherst, University of Notre Dame, Northeastern University
📄 查看 ArXiv 原文
研究背景与痛点
对话搜索比单轮搜索难得多,因为用户意图在多轮交互中持续演化。传统 conversational search pipeline 常采用 rewrite → retrieve → generate 的静态链路,但这很难端到端优化,也很难处理主动澄清、拒答等 mixed-initiative 行为。
另一方面,近年的 deep search agent 又几乎都聚焦单轮任务,缺少对多轮上下文的情境化 reasoning 能力。
核心贡献
- 提出一个面向多轮对话的 agentic conversational search 框架。
- 让模型在 think / search / answer / clarify / noanswer 等动作间自主切换。
- 将 RL 奖励拆成 outcome、information gain、mixed-initiative action 三部分。
- 在多个 conversational benchmark 上超越 pipeline 方法与单轮 search agent 基线。
具体案例剖析
一个典型 multi-turn case 是:用户前几轮先问某类产品、服务或实体,随后再问“有没有替代方案”“哪个更适合我”“那它的缺点呢”。这类后续问题往往无法脱离上下文独立理解。
高质量 agent 的行为不是直接回答,而是先结合历史上下文生成 contextualized query,再根据搜索结果决定是回答、澄清还是拒答。例如:
<think> 判断当前问题依赖上文意图。<search> 生成带上下文实体与约束的搜索查询。- 若结果歧义大,则输出
<clarify>;若证据不足,则输出 <noanswer>。
这说明它做的不是“对话重写器”,而是真正具备 mixed-initiative decision 的搜索 agent。
方法论与技术实现
论文最关键的设计,是把奖励拆成三部分:
- Outcome reward: 最终答案质量。
- Information Gain reward: 搜索返回文档对标准答案的覆盖程度。
- Mixed-Initiative Action reward: 模型是否在该澄清时澄清、该拒答时拒答。
搜索增益奖励可以理解为:不用人工标注“标准 rewrite query”,而直接看你搜回来的文档是否包含正确答案信息。这是非常实用的弱监督思路。
总奖励近似写为:
$$\mathcal{R}(\tau)=\mathcal{R}_{\mathrm{outcome}}+0.5\,(\mathcal{R}_{\mathrm{IG}}+\mathcal{R}_{\mathrm{MIA}})$$
优化上使用 GRPO,而不是传统 PPO,这对长轨迹 agent 训练更稳定。
实验设置与结论分析
- 在 TopiOCQA、INSCIT、QReCC、CORAL 等 benchmark 上全面优于强基线。
- Information Gain reward 去掉后,性能明显下降,说明搜索中间态监督非常关键。
- Mixed-initiative 奖励显著提高了模型的澄清/拒答质量,让它更像真实可用的 assistant。
关键技术亮点分析
- 它真正填补了 single-turn deep search 与 multi-turn conversational search 之间的空白。
- Information Gain reward 是很漂亮的 reward shaping 设计,避免昂贵的人标 query rewrite 数据。
- 把 clarify / noanswer 纳入动作空间并做 RL 对齐,对企业级问答助手尤其重要。