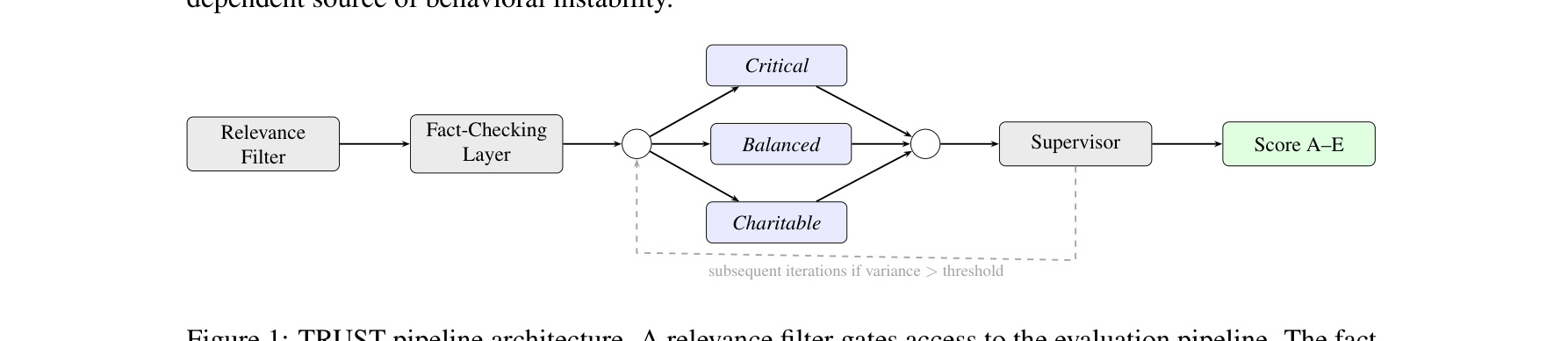
Figures as Interfaces: Toward LLM-Native Artifacts for Scientific Discovery
图表即接口:迈向用于科学发现的LLM原生工件
第一作者:Yifang Wang
核心机构:Northwestern University (西北大学)
🔍 研究背景与痛点
在科学计算和数据分析领域,图表(Figures)长期以来一直是展示复杂数据的最终输出端。随着大语言模型(LLMs)的引入,虽然自动化数据分析和图表生成能力有了巨大提升(如自动生成代码进行可视化),但目前的大多数人机协作系统仍面临以下痛点:
- 图表沦为“一次性”静态图片(Static Endpoint): 图表一旦渲染完成,即被降维成像素或简单的Caption。当人类或多模态LLM想要对其进一步操作时,只能重新通过图像识别来理解,丢失了底层的语义。
- 缺乏探索溯源(Provenance Loss): 科学发现是一个非线性、迭代的过程。现有的分析对话流通常是线性的,一旦上下文过长或分析分叉,就很难追溯某个具体的可视化洞察是由哪段代码、哪个数据集版本生成的,导致复现和二次推理困难。
- 割裂的交互模态: 目前的LLM交互强依赖于纯自然语言输入(LUI)。然而,在数据探索中,诸如框选(Brushing)、点击特定点等图形用户界面(GUI)交互具有不可替代的高效性。现存系统往往无法将这些GUI操作实时反向映射为底层SQL或代码逻辑。
💡 核心贡献
本文提出了一种全新的范式,将科学图表从“静态端点”重新定义为“可查询、可扩展、可复现”的LLM原生工件(LLM-Native Figures)。其核心贡献包括:
- 双重可读的表示法(Dual-Legibility): 设计了一种同时满足人类视觉阅读和机器可计算寻址的图表表示架构。每个图表都内嵌了完整的数据集状态、分析代码、可视化规范及其交互元数据。
- 双向映射机制(Bidirectional Mapping): 构建了“分析操作 $\rightarrow$ 可视化”和“可视化交互 $\rightarrow$ 分析操作”的双向通道。这使得LLM能够“看透”图表,将用户的UI点击/框选无缝转换为底层的过滤/聚合代码。
- 数据驱动的工件网络(Data-Driven Artifacts): 提出将探索过程封装为基于版本的有向无环图(DAG),记录每一组图表之间的协同关系(Coordination)和探索轨迹,实现完美的可审计性(Auditability)。
- 实例化系统 Nexus: 在“科学学(Science of Science, SciSci)”领域实现了一个全栈多智能体系统,验证了该概念在复杂数据集(文献、专利、学者特征)上的实战能力。
🎯 具体案例剖析
论文通过 Nexus 系统 在大学创新图谱(SciSci Domain)的探索任务,展示了人机混合主动式(Mixed-Initiative)的分析流:
- Step 1: 自然语言生成(LUI驱动)
用户输入: “显示基于发明披露数量(Y轴)和被专利引用的论文数(X轴)的发明者分布情况。”
系统响应: LLM自动选择表、编写SQL聚合数据、生成Vega-Lite代码,返回一个交互式散点图。 - Step 2: 基于图表的自然语言修改(Artifact Manipulation)
用户输入(观察到数据长尾聚集严重): “更新图表,将XY轴转为对数刻度,使用公式 $x = \log(x+1)$ 避免零值。”
系统响应: 提取原图表的底层Dataframe和Code,通过数据转换(derive_column)重新生成更加清晰的对数刻度散点图。 - Step 3: 多模态联动钻取(GUI+LUI 深度探索)
用户操作: 使用鼠标在散点图右上角直接框选(Brush)一批“高产出发明者”,并补充文字提问:“用柱状图展示这个群体的部门分布。”
系统响应: 触发Visual $\rightarrow$ Analytical映射。系统捕捉框选区域的数据点ID,将其转化为SQLWHERE从句的过滤条件,并与自然语言指令融合。生成一张新的柱状图,且两张图之间建立协同链接(Coordination Link)。当用户在散点图上拖动框选区域时,柱状图会自动实时刷新。
在这个Case中,不仅得到了业务洞察(比如很多被高频引用的年轻学者未提交发明披露),更关键的是,这一套“过滤-重组-可视化”的操作被永久封装为了一个 Artifact,后续随时可以回退或分叉探索。
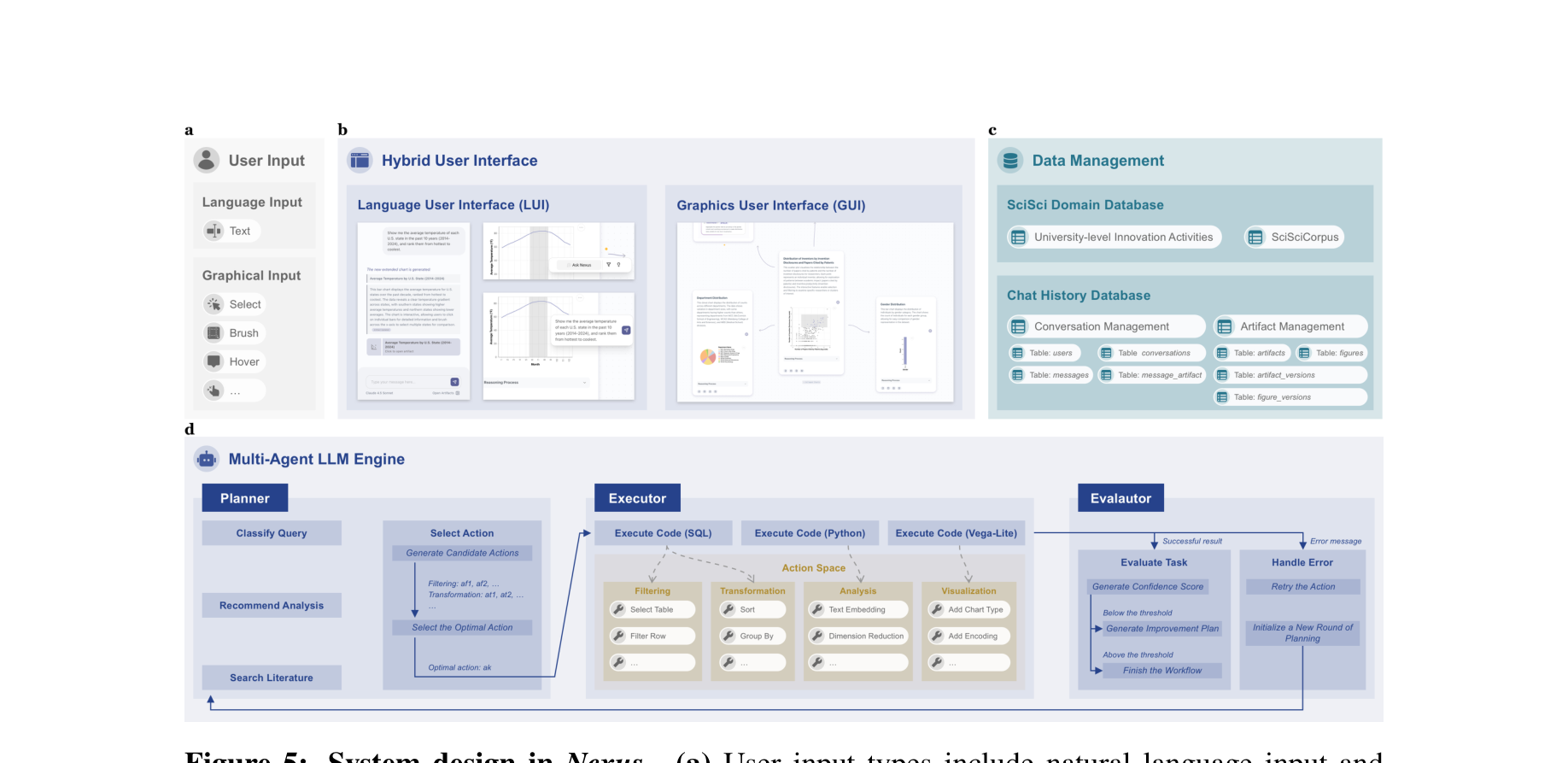
🛠️ 方法论与技术实现
为了让图表兼具表现力和可计算性,论文构建了紧密的软硬件范式设计。
1. 图表的数学抽象 (Representation of LLM-Native Figures)
在 $t$ 时刻生成的每一个图表状态被严谨地定义为一个元组:
$F_t = \{V_t, C_t, D_t, M_t\}$
- $V_t$ (Visual): 渲染的可视化(包括图像、Vega-Lite声明式规范、图表见解文本)。
- $C_t$ (Code): 生成该数据的分析操作与可执行代码(SQL、Python)。
- $D_t$ (Data): 可视化背后挂载的具体数据子集和Schema。
- $M_t$ (Metadata): 溯源元数据(时间戳、版本ID、用户操作日志、以及与其他图表的链接坐标)。
2. 多智能体引擎核心机制 (Multi-Agent LLM Engine)
基于 Plan-Action-Observation 循环机制设计的后端引擎包含三个核心Agent:
- Planner Agent (规划器): 接收LUI和GUI的混合输入。利用基于树状搜索(类似 Tree-of-Thoughts)的策略评估探索路径。它被约束在一个严格定义的动作空间 (Action Space) 内操作(如:过滤、转换、图表类型、编码映射),这大幅降低了幻觉。
- Executor Agent (执行器): 将规划器输出的原子动作转化为具体的代码,在安全的沙箱环境中运行。分为
execute_SQL(),execute_Python(),和execute_VegaLite(),分别负责获取数据、计算模型和渲染图形。 - Evaluator Agent (评估器): 引入了 Self-Reflection 机制。当代码执行报错(如SQL语法错误)或结果偏离预期时,评估器会拦截错误日志并抛回给规划器进行下一轮纠错重试;若通过,则打包成上述的 $F_t$ 元组反馈给前端。
3. UI交互到SQL引擎的反向编译
这是该框架最硬核的工程点:当用户在界面上进行 Continuous Range Brush(比如框选X轴的[1990, 2000])或 Discrete Click(点击某几个类目)时,系统不仅是让前端的高亮变化,而是将这些视觉交互转换回带状态的SQL谓词(如 BETWEEN 1990 AND 2000 或 IN ('A', 'B')),进而将新数据源送给LLM来响应用户的补充提问。
📊 实验设置与结论分析
不同于侧重于人类主观感受的用户研究,本文主要通过计算评估(Computational Evaluation)验证系统作为可靠计算接口的可行性。研究团队利用大模型生成了308个复杂的测试用例(包含初始图表生成、基于图表的交互追问、多图表协同更新)。
- Analytical $\rightarrow$ Visualization (代码生成与图表渲染): 针对用户的初始问题,系统能以 96.7% 的执行成功率跑通全流程,并在语义和逻辑的端到端正确率(End-to-End Accuracy)上达到 92.7%。主要错误来源是数据库专有名词的模糊匹配失败。
- Visualization $\rightarrow$ Analytical (基于交互的溯源解析): 当用户框选图表并提出追问时,系统识别所选数据块并正确组装底层过滤SQL的端到端准确率为 79.8%。研究指出,将视觉的连续选择精确翻译为SQL域条件是难点(易出现边缘范围判定偏差),但在多图表自动联动(Coordination)的测试中,准确率回升到了优异的 91.0%。
结论: 实验证明,通过严格规范的数据上下文和Action Space,大语言模型具备极高保真度的双向编译能力,足以支撑复杂的科学探索闭环。
✨ 关键技术亮点分析
对于资深LLM从业者而言,本文提供了几个非常有价值的启发:
- Compositional Interpretability(组合式可解释性): 传统的LLM输出一旦离开Chat界面就变成了“死数据”。本文将LLM的产出设计成了一个携带了状态机的“微型软件(Artifact)”。这种思路与当下推崇的
Claude Artifacts理念一脉相承,但将其深度下沉到了数据层和分析层。 - 从“端到端问答”转向“非线性状态流转”: 将科研场景解耦为一系列原语(Data Filtering, Transformation, Visual Encoding)。LLM在这里不再是黑盒回答问题的机器,而是成为了一个计算编排器(Orchestrator)。这种设计为复杂的Data Agent指明了技术落地路径,通过约束Action Space极大提升了Agent执行的确定性。
- 多模态对齐的新解法: 通常我们在做多模态图表理解时,依赖Vision Model去“看”图(易引发像素解析错误)。而本作通过底层映射表,让LLM直接去操作图表背后的 AST(抽象语法树)或 JSON Schema,这是一种更优雅、更确定、算力成本更低的多模态人机交互范式。